 New
New
 Free
Free
 Home
Home


Apache Spark is an open-source distributed system that offers a fast and flexible platform for data processing and analysis. It is designed to handle big data processing tasks and can process large datasets in parallel across a cluster of computers. With its powerful engine and flexible APIs, Apache Spark has become a popular choice for data scientists and developers who require a scalable framework for processing and analyzing large datasets. In this article, we will explore some of the key features of Apache Spark and how it can be used for data processing and analysis.
Usage: Productivity
Pricing: Free - Free (open source)
Tags: open-source data scientists analysis data processing fast
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts | Contact Info


Product Screenshots
Video Reviews
Similar Tools to Apache Spark
-
Automate your documents within minutes and reduce tedious, repetitive tasks. Optimize your business with an all-in-one contract and workflow automation solution. #1 Documents & web forms 📝 #2 No-code visual workflows 🚀 #3 Pipeline automation ⚙️
 Contact for Rates
#Automation
Contact for Rates
#Automation
-
Pythagora is a cutting-edge automated tool for integration testing that revolutionizes the way developers test their server applications. Unlike traditional testing methods, Pythagora does not require users to write any code. Instead, it analyzes server activity and creates tests based on the data obtained. The tool is incredibly user-friendly, requiring only a simple installation with npm, followed by a capturing command, then a test command. With Pythagora, developers can ensure that their applications are functioning optimally without the hassle of manual testing.
Contact for Rates
#Automation
-
Form.com is an innovative AI-driven platform designed to automate forms and surveys, minimizing human errors, saving valuable time and money, and enhancing customer experiences. The platform leverages cutting-edge technology to streamline data collection, processing, and analysis, providing businesses with actionable insights to improve their operations and customer engagement. With its user-friendly interface and powerful features, Form.com simplifies the form and survey creation process while ensuring accuracy and completeness. This platform is a game-changer for organizations looking to optimize their workflows, reduce costs, and enhance customer satisfaction.
Contact for Rates
#Automation
-
Google Cloud Platform is a revolutionary suite of cloud computing services that offers users the ability to build, deploy, and manage various applications. It provides an extensive range of tools and features that cater to businesses of all sizes, thereby ensuring a seamless and efficient workflow. Google Cloud Platform is designed to deliver high-performance computing resources, storage, and networking capabilities while adhering to stringent security protocols. With its flexibility and scalability, it has become the go-to choice for many organizations that require reliable and cost-effective cloud solutions.
Free
#Automation
-
Flexberry AI Assistant is a revolutionary tool that has been specifically designed to cater to the needs of business analysts. It aims to reduce the time spent on processing requirements and generating artifacts by automatically extracting information from natural language and structuring it into categories. The AI assistant also builds project metadata, generates diagrams and prototypes, and analyses statements and requirements for completeness. With its advanced capabilities, Flexberry AI Assistant is set to transform the way in which business analysts work, enabling them to be more efficient and productive.
Contact for Rates
#Automation
-
Diffblue is an AI-powered unit testing platform that helps software developers test their code with greater accuracy and efficiency. It provides developers with the ability to quickly and easily generate automated tests for their code, thus reducing time and cost associated with manual testing. Diffblue's AI technology also enables developers to uncover more bugs and edge cases, thus improving the overall quality of their code.
Contact for Rates
#Automation

Top Rated Tools
-
GPT-3 Road Trip Plans For 2021 By CarMax
AI Plans a Road Trip | CarMax
Contact for Rates #Others -
YouChat
AI Chatbot Builder
Contact for Rates #Search Engine -
Wolframalpha
Wolfram|Alpha: Computational Intelligence
Freemium #Knowledge Base -
RestorePhotos
Face Photo Restorer
Free #Image Editing -
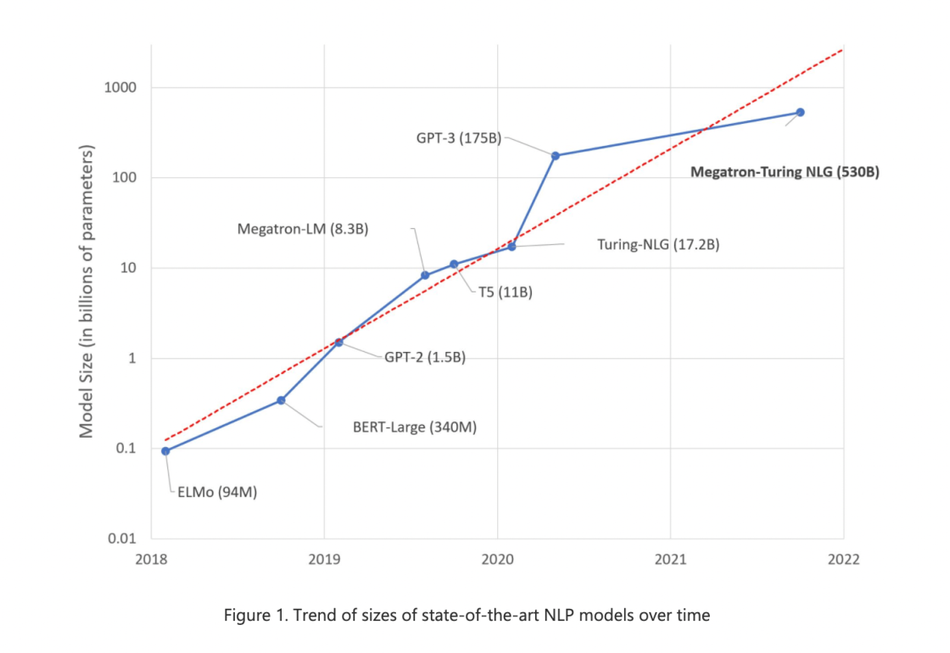
Megatron NLG
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model | NVIDIA Technical Blog
Contact for Rates #Alternative Language Model -
TwitterBio
AI Twitter Bio Generator – Vercel
-
Make (fomerly Known As Integromat)
Automation Platform
Contact for Rates #Automation -
Nijijourney
NijiJourney AI for the anime fans. The new niji model is tuned with a fine eye to produce anime and illustrative styles. It has vastly more knowledge of anime, anime styles, and anime aesthetics. It's great at dynamic and action shots, and character-focused compositions in general.
Free Trial #Generative AI



Apache Spark is a powerful open-source distributed system that has revolutionized the way data is processed and analyzed. It was originally developed at the University of California, Berkeley's AMPLab in 2009 and later donated to the Apache Software Foundation in 2013. Since then, it has become one of the most popular big data processing engines, offering a fast, flexible, and efficient way to handle large-scale data processing tasks. With its high-performance computing capabilities, Spark can process large amounts of data up to 100 times faster than traditional Hadoop MapReduce. The system is built on top of the Hadoop Distributed File System (HDFS) and provides APIs for various languages such as Java, Scala, Python, R, and SQL. Spark is also highly versatile and can be used for batch processing, stream processing, machine learning, and graph processing. It has gained wide adoption across various industries, including finance, healthcare, retail, and telecommunications, making it an essential tool for any organization dealing with large-scale data processing and analysis.

Top FAQ on Apache Spark
1. What is Apache Spark?
Apache Spark is an open source distributed system for data processing and analysis that can handle large-scale data processing in real-time.
2. What are the benefits of using Apache Spark?
Apache Spark offers several benefits such as faster processing speed, fault tolerance, and support for multiple programming languages.
3. What programming languages does Apache Spark support?
Apache Spark supports several programming languages, including Python, Java, Scala, R, and SQL.
4. How does Apache Spark differ from Hadoop?
Apache Spark is a faster and more flexible alternative to Hadoop, it can process data in real-time and offers support for multiple programming languages.
5. What types of data processing can be done using Apache Spark?
Apache Spark can be used for various types of data processing, including batch processing, stream processing, machine learning, graph processing, and SQL-based processing.
6. How does Apache Spark handle large datasets?
Apache Spark uses a distributed computing model, dividing large datasets into smaller chunks that can be processed in parallel across multiple nodes.
7. Can Apache Spark be used for real-time processing?
Yes, Apache Spark can be used for real-time processing through its stream processing capabilities.
8. Is Apache Spark difficult to learn?
Apache Spark can have a steep learning curve, especially for beginners. However, there are many resources available online for learning and mastering the technology.
9. What companies use Apache Spark?
Many large companies use Apache Spark for their data processing needs, including Netflix, IBM, Yahoo, and eBay.
10. Is Apache Spark free to use?
Yes, Apache Spark is an open source project and is free to use. However, some commercial distributions of Apache Spark may require a license fee.
11. Are there any alternatives to Apache Spark?
| Apache Spark | Apache Flink | Apache Hadoop | IBM InfoSphere BigInsights |
|---|---|---|---|
| Open source distributed system for data processing and analysis | Open source stream processing framework | Open source big data processing framework | Commercial big data analytics platform |
| Written in Scala, Java, Python and R | Written in Java and Scala | Written in Java | Written in Java |
| Supports batch processing, streaming, machine learning and graph processing | Supports stream processing and batch processing | Supports batch processing and real-time processing | Supports batch processing and real-time processing |
| Provides high-level APIs in Java, Scala and Python | Provides APIs in Java and Scala | Provides APIs in Java | Provides APIs in Java |
| Has a strong community support | Has a growing community support | Has a strong community support | Has a commercial support |

Pros and Cons of Apache Spark
Pros
- High processing speed: Apache Spark can process large datasets in a fraction of the time that traditional Hadoop systems would take.
- Easy to use: Spark has a user-friendly API that allows data analysts and developers to write code more easily than with other big data processing systems.
- Scalability: Spark is designed to scale up or down depending on the size of the dataset being analyzed.
- Flexibility: Spark can be used for a wide range of data processing tasks, including batch processing, real-time stream processing, machine learning, and graph processing.
- Cost-effective: As an open-source software, Spark is free to use, which makes it an ideal choice for businesses that want to save on software costs.
- Community support: Spark has a vibrant community of developers who contribute to its development, provide support, and create plugins and libraries to extend its functionality.
- Integration with other technologies: Spark integrates with other big data technologies like Hadoop, NoSQL databases, and cloud services, making it versatile and easy to use in different environments.
Cons
- Steep learning curve for beginners
- Requires significant hardware resources to run efficiently
- Limited support for non-JVM languages
- Lack of built-in security features
- Difficulty in debugging and troubleshooting errors
- Limited integration with other data processing tools and systems
- Relatively new technology with a less established user community compared to other data processing tools.

Things You Didn't Know About Apache Spark
Apache Spark is an open-source distributed system that is designed for data processing and analysis. It is a fast and powerful engine that can process large amounts of data in real-time. Spark has become one of the most popular big data processing frameworks due to its ease of use, flexibility, and scalability. Here are some essential things you should know about Apache Spark:
1. Spark is built for speed: Spark is designed to be faster than Hadoop MapReduce for batch processing, SQL queries, and streaming analytics. It achieves this by using in-memory caching and optimized query execution plans.
2. It supports multiple languages: Spark provides APIs for programming in Java, Scala, Python, and R. This allows developers to choose the language they are most comfortable with while still being able to use Spark.
3. It has a wide range of use cases: Spark can be used for various data processing tasks such as batch processing, real-time processing, machine learning, graph processing, and more. It is suitable for both small and large datasets.
4. Spark runs on a cluster: Spark can run on a cluster of machines, making it easy to scale horizontally. It uses a master-slave architecture where a driver program runs on a master node, and worker nodes execute the tasks.
5. It has a rich ecosystem: Spark has a vast ecosystem of libraries and tools such as Spark SQL, Spark Streaming, MLlib, GraphX, and more. These libraries make it easy to perform complex data processing tasks.
6. Spark supports multiple data sources: Spark can process data from various sources, including Hadoop Distributed File System (HDFS), Cassandra, Amazon S3, and more. It also supports different data formats such as Parquet, Avro, and JSON.
7. It has an active community: Spark has a large and active community of contributors and users, making it easy to get help and support when needed. The community regularly releases new versions with bug fixes and new features.
In conclusion, Apache Spark is a powerful and flexible distributed system for data processing and analysis. It has become the go-to framework for big data processing due to its speed, scalability, and ease of use. With its vast ecosystem of libraries and tools, Spark can handle a wide range of data processing tasks, making it an essential tool for data scientists and developers.
Get in touch with Apache Spark

edited by
Emily Collins is a freelance writer with over a decade of experience in the field. Emily has a passion for all things tech, especially AI-powered tools and GPT-3 & GPT-4 apps. She is a self-proclaimed geek and developer, always looking for the latest and greatest in software and coding. When she's not writing, Emily can usually be found tinkering with her computer, playing video games, or reading science fiction novels. With her unique combination of writing skills and tech expertise, Emily is a valuable asset to any project she takes on.


