 New
New
 Free
Free
 Home
Home

The coqui frog, native to Puerto Rico, is more than just a beloved symbol of Puerto Rican heritage; it is also a symbol of freedom of speech. Coqui frogs are known for their distinct call, which has been used to represent freedom of expression since the Spanish colonization of Puerto Rico centuries ago. Today, the coqui frog continues to be a symbol of liberation and an important part of Puerto Rican identity. This article will explore the history of coqui frogs as a symbol of free speech and how they have been used to empower the people of Puerto Rico.
Pricing: Paid
Tags: technology businesses customer service individuals audio content
For more information, jump to:
Screenshots | Videos | Similar Tools | Pricing and Features | FAQs | Pros and Cons | Facts | Contact Info


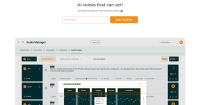
Product Screenshots
Video Reviews
Similar Tools to Coqui
-
Orion Labs Onyx is an innovative AI-powered voice platform that enables users to create complex conversational applications with ease. With its cutting-edge technology, Orion Labs Onyx empowers developers to build sophisticated voice applications that can understand natural language and respond accordingly. The platform's intuitive interface allows users to quickly create custom voice experiences that seamlessly integrate with various devices and platforms. Orion Labs Onyx is a game-changer for businesses and developers looking to enhance their customer experience by providing a more personalized and engaging voice interaction.
 Paid
#Speech Synthesis
Paid
#Speech Synthesis
-
CereVoice Cloud is a revolutionary technology that offers high-quality and natural-sounding Text-to-Speech (TTS) capabilities. It provides a range of voices that are specifically designed to meet the needs of various industries, including gaming, e-learning, and entertainment. With its advanced features and intuitive interface, CereVoice Cloud represents the future of TTS technology, enabling businesses to create engaging and interactive digital experiences for their customers. In this article, we will explore the benefits of CereVoice Cloud and how it can help businesses enhance their online presence and customer engagement.
Paid
#Speech Synthesis
-
IBM's Speech to Text service is a cutting-edge technology that utilizes sophisticated deep learning neural network algorithms to convert spoken language into written text. This innovative technology is highly sought-after in industries such as healthcare, education, legal, and media. IBM's Speech to Text service enables users to transcribe audio recordings and live speech, thereby saving valuable time and resources. With its exceptional accuracy and efficiency, this powerful tool has become an indispensable asset for businesses looking to improve their communication and productivity.
Paid
#Speech Synthesis
-
TEMI is a cutting-edge technology that has revolutionized the way brands and organizations analyze customer feedback. This innovative tool utilizes speech recognition and natural language processing to provide insights into customer sentiment and preferences. With TEMI, businesses can gain a deeper understanding of their audience, allowing them to make informed decisions and improve their overall performance. As a result, companies can enhance customer satisfaction, increase loyalty, and ultimately drive revenue growth.
Free Trial
#Speech Synthesis
-
Microsoft Speech Recognition is a cutting-edge cloud-based solution that empowers developers to integrate speech-to-text features into their applications. This remarkable technology allows users to interact with their devices using spoken words, which are then transcribed into text format. With Microsoft Speech Recognition, developers can create innovative applications that enable users to communicate more efficiently and effectively, whether it's for personal or business use. This service is designed to provide a seamless and effortless experience, making it an ideal tool for developers looking to enhance their applications' functionality.
Contact for Rates
#Speech Synthesis
-
Welcome to Altered! Our revolutionary technology allows you to transform your voice into something completely different. Imagine being able to change your voice to any of our carefully curated voices or even create your own custom voice. From a soothing natural voice to a deep commanding one, our unique portfolio has it all. With us, you can easily create professional and compelling voice performances that will make you stand out. Let Altered be your go-to platform for augmentation and enhancement of your voice.
Paid
#Audio Editing
Top Rated Tools
-
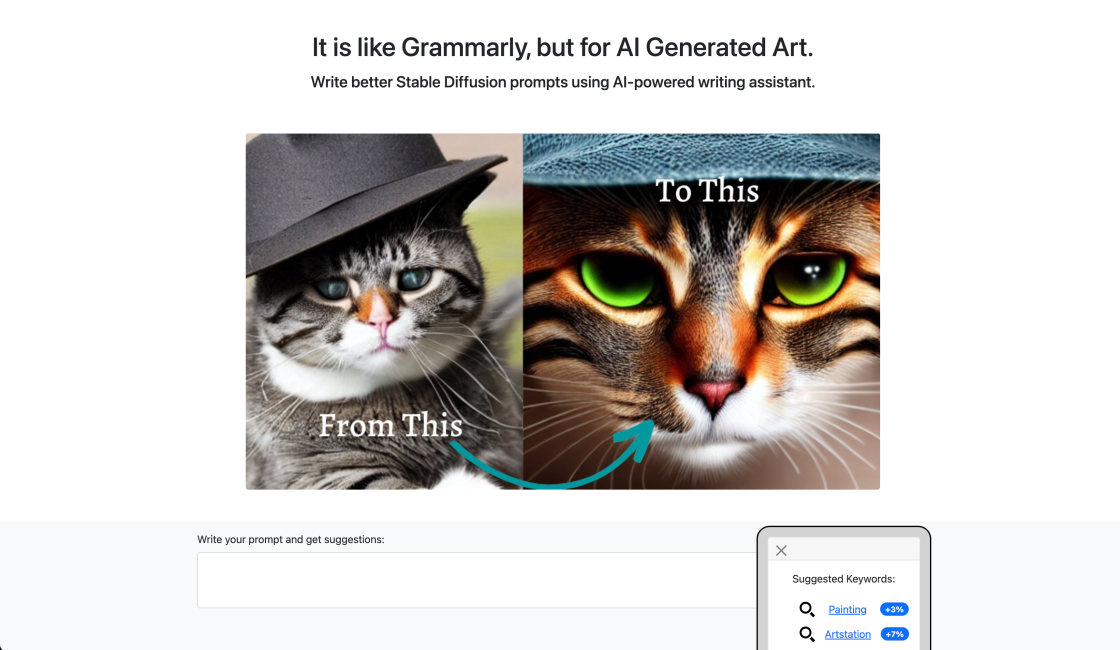
Write Stable Diffusion Prompts
How to Write an Awesome Stable Diffusion Prompt
Contact for Rates #Image Editing -
Jasper
AI-Powered Customer Support
Paid #Others -
Wordtune
Wordtune | Your personal writing assistant & editor
Paid #Paraphrasing -
TinyWow
Free AI Writing, PDF, Image, and other Online Tools - TinyWow
Free #Life Assistant -
PhotoRoom
PhotoRoom - Remove Background and Create Product Pictures
Freemium #Generative AI -
Speechify
Best Free Text To Speech Voice Reader | Speechify
Paid #Productivity -
Pictory
AI-Generated Storytelling
Paid #Text Editing -
LALAL.AI
LALAL.AI: 100% AI-Powered Vocal and Instrumental Tracks Remover
Freemium #Audio Editing



Coqui, the generative AI voice technology, has revolutionized the way we interact with artificial intelligence. It is a powerful tool that allows users to create unique and realistic voices for their applications, devices, or content. The technology uses deep learning algorithms to analyze and mimic human speech patterns, intonations, and accents, making it possible to generate a wide variety of voices in different languages and dialects.
Since its introduction, Coqui has found extensive use in several industries, including entertainment, education, and customer service. Its ability to produce human-like voices has made it an indispensable tool for creating engaging and interactive content that resonates with audiences. With Coqui, developers can create natural-sounding speech interfaces that improve user experience and boost engagement.
Moreover, the technology has also garnered significant attention for its potential to democratize voice technology. Coqui's open-source nature allows developers to build and customize their own voice models, enabling them to create innovative solutions for their unique needs. This affordability and flexibility make Coqui an accessible tool for businesses and individuals alike, making it a go-to choice for anyone looking to incorporate AI-generated voices into their projects.

Pricing and Features of Coqui
| Plan | Cost | Features |
|---|---|---|
| Free | 0 | 30 mins synthesis time, Unlimited Voice Cloning, Generative AI Voices and Emotions, Unlimited Projects & Scripts, Directable Voice Pacing, Intonation, and Intensity |
| Starter | $20 | 4 hours of synthesized audio, Unlimited Voice Cloning, Generative AI Voices and Emotions, Unlimited Projects & Scripts, Directable Voice Pacing, Intonation, and Intensity |
| Pro | Everything in Starter, plus: Multi-user, Team Collaboration Tools, Higher Quality Voice Clones, Multi-lingual synthesis, Pro-Level Support | |
| Enterprise | Custom Quote | Everything in Pro, plus: Single Sign On (SSO), Role-Based Access (RBAC), Team Management Tools, Premium Quality Voice Clones, All Supported Languages, Script Versioning, Audit Logs, Virtual Private Cloud Hosting, Custom Integrations, API access |

Top FAQ on Coqui
1. What is Coqui?
Coqui is a set of open-source speech synthesis models for text-to-speech generation built on machine learning algorithms.
2. How does Coqui generate AI voices?
Coqui generates AI voices using deep neural networks that learn from large amounts of speech data to create natural-sounding voices.
3. Can Coqui's AI voices be used for commercial purposes?
Yes, Coqui's AI voices can be used for commercial purposes as they are released under the Apache 2.0 license.
4. What languages does Coqui support?
Currently, Coqui supports several languages including English, Spanish, French, German, and Italian.
5. Can Coqui generate accents and dialects?
Yes, Coqui can generate accents and dialects by training its models on specific regional speech patterns.
6. What kind of applications can use Coqui's AI voices?
Coqui's AI voices can be used in a wide range of applications such as virtual assistants, audiobooks, and automated customer service systems.
7. How accurate are Coqui's AI voices?
Coqui's AI voices are highly accurate and produce human-like speech with natural intonation and rhythm.
8. Is Coqui easy to use for non-technical users?
Yes, Coqui is designed to be user-friendly and can be used by non-technical users with minimal programming knowledge.
9. What hardware requirements are needed to run Coqui?
Coqui can be run on a variety of hardware platforms, including CPUs, GPUs, and mobile devices.
10. Where can I learn more about Coqui and its capabilities?
You can visit Coqui's official website to learn more about its features, documentation, and community support.
11. Are there any alternatives to Coqui?
| Competitor | Difference from Coqui - Generative AI Voices |
|---|---|
| Google Cloud Text-to-Speech | Offers more natural sounding voices and a wider variety of voice options. |
| Amazon Polly | Offers more languages and voices than Coqui, as well as integration with other Amazon services. |
| IBM Watson Text to Speech | Offers advanced customization options, such as the ability to control tone and pitch, and supports multiple languages. |
| Microsoft Azure Text-to-Speech | Offers more natural sounding voices and customization options, as well as integration with other Microsoft services. |
| NaturalReader | Offers a more user-friendly interface and a wider range of reading materials, including web pages and PDFs. |
| Acapela Group | Offers a wide range of voices in multiple languages and can be integrated with various platforms and devices. |
| CereProc | Offers highly customizable voices with specific accents and dialects, as well as integration with various platforms and devices. |
| ReadSpeaker | Offers a wide range of voices in multiple languages and customization options, as well as integration with various platforms and devices. |

Pros and Cons of Coqui
Pros
- Coqui can create realistic and natural-sounding AI-generated voices that can mimic human speech patterns and intonations.
- It allows for the creation of custom voices for specific applications, such as voice assistants or audiobook narrators.
- The software is open-source and freely available, making it accessible to developers and researchers around the world.
- Coqui can be trained on a variety of languages and accents, enabling it to produce voices for a diverse range of communities and cultures.
- The tool can be used to generate synthetic speech for people with speech impairments or disabilities, providing them with a way to communicate more effectively.
- Coqui can help reduce the time and cost involved in creating high-quality voiceovers for videos, podcasts, and other media content.
- The technology has the potential to revolutionize the field of text-to-speech (TTS) synthesis, making it easier and more affordable to generate natural-sounding speech.
Cons
- Lack of emotional depth and nuance in the voices generated by Coqui AI.
- Limited range of voice styles and tones available.
- Difficulty in training the AI to accurately mimic specific human voices.
- Potential for misuse of the technology in creating fake audio recordings or imitating others without their consent.
- Dependence on internet connection and computing power, which may limit accessibility for some users.
- Potential for perpetuating biases and stereotypes if the training data used to create the AI is not diverse and inclusive.

Things You Didn't Know About Coqui
Coqui is a project that aims to create open-source, generative AI voices that can be used for various applications. Here are some things you should know about Coqui and its AI voices:
1. Coqui is an open-source project: Coqui is an open-source initiative that anyone can contribute to. It is sponsored by Mozilla and the Common Voice project, which aims to make voice recognition technology more accessible and inclusive.
2. Coqui uses deep learning: The AI voices generated by Coqui are based on deep learning techniques. The models are trained on large datasets of human speech, which allows them to learn how to generate realistic-sounding voices.
3. Coqui has different voice models: Coqui currently has two main voice models: Tacotron 2 and WaveGlow. Tacotron 2 is a text-to-speech model that can generate natural-sounding speech from written text. WaveGlow is a neural vocoder that can synthesize high-quality audio from Tacotron 2's output.
4. Coqui's voices are multilingual: Coqui's voice models can be trained on speech data in different languages, which means that they can generate voices in multiple languages. This makes them useful for applications that require multilingual support.
5. Coqui's voices are free to use: Because Coqui is an open-source project, its voices are free to use for any purpose. This makes them an attractive option for developers who want to add voice capabilities to their applications without having to pay for expensive proprietary solutions.
Overall, Coqui is an exciting initiative that has the potential to democratize voice recognition technology and make it more accessible to everyone. Its generative AI voices are a testament to the power of deep learning and the benefits of open-source collaboration.
Get in touch with Coqui

edited by
Jack Richards is a self-proclaimed geek and AI enthusiast who has been freelancing as a writer for over a decade. With a rich writing experience in various niches, Jack's love for technology led him to explore the world of AI-powered tools and GPT-3 & GPT-4 apps. He has been fascinated with the possibilities that AI can bring to the writing world, and spends much of his time experimenting with different tools and software. Jack's passion for writing and technology has led him to create some of the most unique and thought-provoking content in his field, making him a recognized name among the writing community.


