 New
New
 Free
Free
 Home
Home


ImageNet is an AI-based image database that has revolutionized the field of computer vision. This vast collection of images has been labeled and categorized to train machine learning algorithms to identify and classify objects accurately. ImageNet has played a crucial role in the development of deep learning models and has helped to advance the state-of-the-art in object recognition. With its enormous scale and high quality, ImageNet has become a benchmark dataset for researchers and practitioners alike. In this paper, we examine the history and impact of ImageNet on the field of computer vision and explore its potential for future research.
Usage: Other
Pricing: Free - Free
Tags: machine learning algorithms researchers computer vision deep learning models object recognition
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts | Contact Info


Product Screenshots
Video Reviews
Similar Tools to ImageNet
-
U-Net is a revolutionary deep learning model that has been widely used for image segmentation. The model has gained popularity due to its ability to accurately segment images, making it an essential tool in fields such as medical imaging, robotics, and autonomous driving. U-Net has received attention from researchers and developers for its remarkable performance, and its architecture has become a benchmark for many image segmentation tasks. This introduction aims to provide insight into the U-Net model, its architecture, and its applications.
 Contact for Rates
#Computer Vision
Contact for Rates
#Computer Vision
-
Google Cloud Vision is a reliable and efficient tool for image recognition, capable of identifying multiple elements such as objects, logos, and faces in just seconds. With the help of Cloud Vision API, users can quickly extract valuable insights from images, enabling them to gain a better understanding of visual content. The technology also offers high accuracy and precision, making it an ideal choice for businesses and organizations that require speedy and accurate image analysis.
Contact for Rates
#Computer Vision
-
Google Cloud Vision is an innovative platform that offers advanced image and video recognition and analysis services. With its state-of-the-art algorithms, this vision-as-a-service platform can detect and classify objects, faces, landmarks, and text within images and videos. It can also extract valuable insights from visual data, such as sentiment analysis and optical character recognition. Google Cloud Vision provides businesses with the tools they need to automate their operations, optimize their workflows, and enhance their customer experiences. This article explores the features and benefits of Google Cloud Vision and how it can help companies improve their image and video analysis capabilities.
Paid
#Computer Vision
-
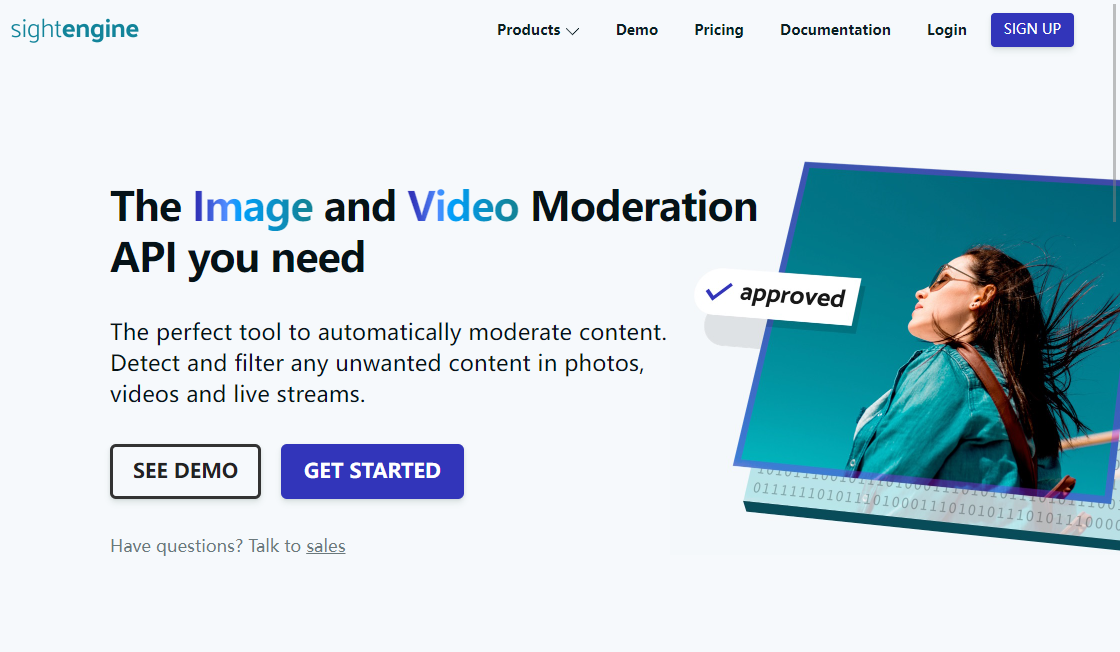
Sightengine is a cutting-edge AI-powered content moderation service that is designed to detect and flag inappropriate images and videos. With its advanced technology, this platform is capable of identifying pornographic content, nudity, violence, drugs, and other forms of inappropriate material. By leveraging the power of artificial intelligence, Sightengine provides a reliable and effective solution for businesses and organizations seeking to protect their online brand reputation and ensure that their content remains safe and appropriate for all audiences.
Paid
#Computer Vision
-
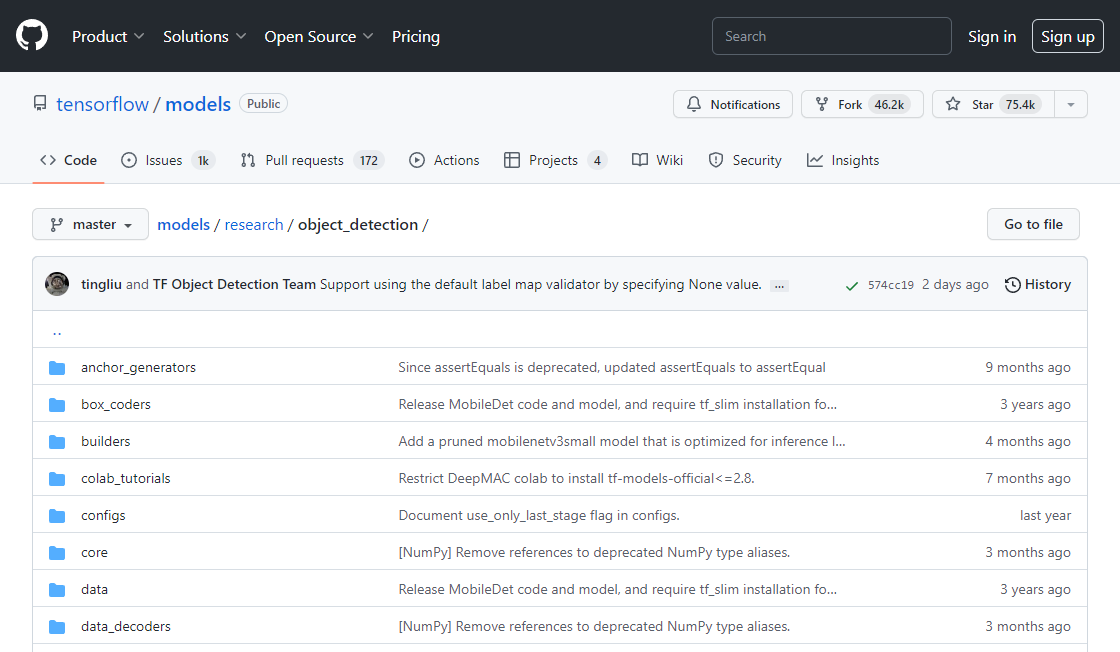
TensorFlow Object Detection API is a widely used open-source software library for object detection from images. This API provides researchers and developers with an efficient way to train and deploy their own customized object detection models. With its powerful set of tools, TensorFlow Object Detection API has been used in various fields such as autonomous driving, robotics, and surveillance. Its user-friendly interface and extensive documentation make it accessible to both beginners and experts alike. In this article, we will explore the features and benefits of TensorFlow Object Detection API in detail.
Free
#Computer Vision
-
Gestualy is a cutting-edge AI-powered gesture recognition system that has revolutionized the way businesses measure customer satisfaction. With its state-of-the-art technology, Gestualy can accurately detect up to 500 different gestures that express various emotions in just seconds, eliminating the need for cumbersome surveys. By harnessing advanced machine learning techniques, Gestualy provides businesses with an effective tool to gauge customer feedback and improve their services accordingly. The innovative technology behind Gestualy is changing the game for customer service and experience, making it easier than ever for businesses to understand their customers' needs and preferences.
Contact for Rates
#Computer Vision

Top Rated Tools
-
PlaygroundAI
A free-to-use online AI image creator
Contact for Rates #Image Editing -
Civitai
Creating Intelligent and Adaptive AI
Free #Art Generation -
GPT For Sheets
GPT for Sheets™ and Docs™ - Google Workspace Marketplace
Free #Generative AI -
Venngage
Valentine’s Day Card Maker
Free #Life Assistant -
Remini
Remini - AI Photo Enhancer
Paid #Image Editing -
Voice.ai
Custom Voice Solutions
Free #Chatbot -
Keeper Tax
Keeper - Taxes made magical
Contact for Rates #Others -
Unbounce
Smart Copy: AI Copywriting & Content Generator Tool | Unbounce
Paid #Writing Assistant

ImageNet is a large-scale, AI-based image database that has revolutionized the field of computer vision. It contains millions of annotated images organized into thousands of categories, making it an invaluable resource for researchers and developers working on image recognition and classification tasks. The creation of ImageNet was a significant milestone in the development of artificial intelligence, as it allowed for the training of deep neural networks that could accurately recognize and categorize objects in images. This breakthrough has led to numerous applications in fields such as self-driving cars, facial recognition, medical diagnosis, and more. The database has also spurred the development of new algorithms and techniques for image processing, such as convolutional neural networks (CNNs), which have become the go-to method for many image recognition tasks. In this paper, we will explore the history and significance of ImageNet, its impact on the field of AI, and some of the exciting applications that have emerged as a result of its creation.

Top FAQ on ImageNet
1. What is ImageNet?
ImageNet is a large-scale image database that uses artificial intelligence (AI) to classify and categorize millions of images.
2. How many images are there in ImageNet?
ImageNet contains over 14 million images, which have been labeled and categorized by humans and machine learning algorithms.
3. What is the purpose of ImageNet?
ImageNet was created to help researchers develop and test computer vision algorithms, as well as to advance the field of AI and machine learning.
4. What types of images are included in ImageNet?
ImageNet includes a wide range of images, including animals, plants, objects, scenes, and people.
5. How is ImageNet different from other image databases?
ImageNet is unique because it uses a hierarchical structure of categories to organize its images, which allows for more precise classification and labeling.
6. Can anyone access ImageNet?
Yes, ImageNet is publicly available and can be accessed by anyone who registers for an account.
7. What are some applications of ImageNet in AI and machine learning?
ImageNet has been used to train and test image recognition systems, object detection algorithms, and even self-driving cars.
8. Who created ImageNet?
ImageNet was created by Fei-Fei Li, a computer science professor at Stanford University, and her research team in 2009.
9. How accurate is ImageNet's image labeling?
ImageNet's image labeling is highly accurate, with a top-5 classification accuracy of over 95%.
10. Is ImageNet still being updated and maintained?
Yes, ImageNet is still being updated and maintained, with new images and categories added regularly to keep up with advancements in AI and machine learning.
11. Are there any alternatives to ImageNet?
| Competitor | Description | Key Features | Differences |
|---|---|---|---|
| Google Cloud Vision API | AI-based image analysis tool | Image labeling, face detection, OCR, object tracking, content moderation | Provides OCR capabilities and more advanced object tracking compared to ImageNet |
| Clarifai | AI-powered image and video recognition | Image and video tagging, NSFW detection, custom model training | Offers custom model training, while ImageNet has a fixed set of pre-trained models |
| Microsoft Azure Computer Vision | Cloud-based image analysis service | Image tagging, OCR, facial recognition, object detection, adult content filtering | Offers facial recognition and adult content filtering, which ImageNet does not |
| IBM Watson Visual Recognition | Cloud-based image analysis tool | Image tagging, face detection, custom model training | Offers custom model training and face detection, while ImageNet has pre-trained models only |
| Amazon Rekognition | AI-powered image and video analysis tool | Face detection, image and video analysis, content moderation, celebrity recognition | Offers celebrity recognition and more advanced video analysis compared to ImageNet |

Pros and Cons of ImageNet
Pros
- Contains over 14 million images in various categories.
- Provides a diverse dataset for machine learning and computer vision research.
- Enables the development of deep learning models and algorithms.
- Improves image recognition accuracy and reduces errors.
- Supports training of artificial neural networks for image classification.
- Helps to advance the field of computer vision and artificial intelligence.
- Used by many researchers, academics, and companies for their projects.
- Offers a standardized benchmark for evaluating image recognition models.
- Allows for transfer learning and reusing pre-trained models.
- Provides a platform for crowdsourcing annotations and labelings.
Cons
- May perpetuate biases and inequalities in society as the dataset was originally curated with a focus on Western culture and may not accurately represent diverse communities.
- Can be exploited to create deepfakes or manipulated images that can be used for malicious purposes such as spreading misinformation or propaganda.
- Privacy concerns as users' personal data may be collected and used without their consent.
- Limited accuracy as the AI model is only as good as the data it is trained on, and ImageNet may not cover all possible image scenarios.
- Potential ethical issues related to the use of AI technology, such as job displacement and increasing reliance on machines over human decision-making.

Things You Didn't Know About ImageNet
ImageNet is a large-scale, AI-based image database that contains over 14 million images and 21,000 categories. It was created in 2009 by a team of researchers at Princeton University led by computer scientist Fei-Fei Li. The goal of ImageNet is to provide a standardized dataset for researchers working on computer vision and machine learning algorithms.
One of the key features of ImageNet is its use of crowdsourcing to label images. Instead of relying on experts to manually label each image, ImageNet uses a process called "tagging." This involves presenting an image to a group of people and asking them to provide descriptive tags that describe the content of the image. The tags are then used to classify the image into one or more of the 21,000 categories in the database.
The size and diversity of ImageNet have made it a valuable resource for researchers working on a wide range of computer vision and machine learning problems. The database has been used to train deep neural networks, which are capable of recognizing objects, faces, and other visual patterns with remarkable accuracy.
One of the most famous applications of ImageNet is the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which is an annual competition that evaluates the performance of computer vision algorithms on a standardized set of images. In 2012, a team from the University of Toronto led by computer scientist Geoffrey Hinton achieved a major breakthrough when they used a deep neural network to achieve a record-low error rate on the ILSVRC dataset. This marked the beginning of the era of deep learning in computer vision and paved the way for a wide range of applications, including self-driving cars, facial recognition, and medical imaging.
Overall, ImageNet has become an essential tool for researchers working on computer vision and machine learning. Its large size, diverse categories, and standardized labeling make it a valuable resource for training and evaluating algorithms. As AI continues to advance, ImageNet will likely continue to play a key role in driving innovation and progress in this field.
Get in touch with ImageNet

edited by
Samantha Lee is a freelance writer with over a decade of experience writing for a variety of industries. She is an avid enthusiast of AI powered tools and GPT-3 & GPT-4 apps, constantly exploring new ways to incorporate these technologies into her work. As a self-proclaimed geek, Samantha spends her free time diving deep into the latest tech gadgets and coding projects. Her writing has been featured in numerous publications and she has won several writing awards. When she's not writing or coding, you can find Samantha hiking or exploring new restaurants in her hometown of San Francisco.


