 New
New
 Free
Free
 Home
Home


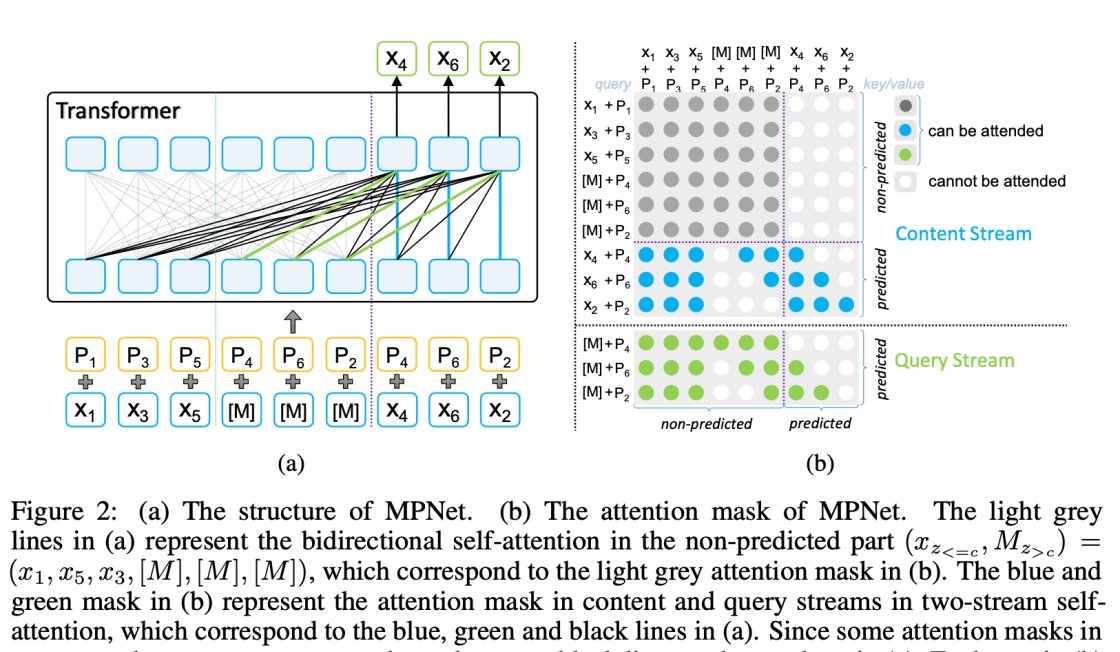
The MPNet model is a state-of-the-art pre-training framework for natural language understanding (NLU) that incorporates a masked and permuted pre-training approach. This method enables the model to learn contextual representations of text by masking and shuffling different sections of the input text, forcing the model to understand the relationships between different parts of the text. MPNet has achieved impressive results on various NLU tasks such as sentiment analysis, question answering, and text classification. Its versatility and effectiveness make it a promising candidate for advancing the field of NLU.
Usage: Education
Model: GitHub
Pricing: Contact for Rates
Tags: sentiment analysis Natural Language Understanding effectiveness versatility text classification
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots
Video Reviews
Similar Tools to MPNet
-
The introduction introduces Endless Academy, an AI-powered learning tool that delivers personalized education on any desired subject. This innovative platform boasts a plethora of features, allowing learners to tailor their educational experience to their precise needs and preferences. With Endless Academy, users can delve into a vast range of topics, all while enjoying an individualized approach that caters to their unique learning style. By harnessing the power of artificial intelligence, this cutting-edge platform revolutionizes the way we acquire knowledge, empowering learners to embark on a limitless educational journey.
 Free Trial
#Learning Assistant
Free Trial
#Learning Assistant
-
The advent of artificial intelligence has revolutionized numerous industries, and now education is no exception. Introducing MagicpathAI, an innovative AI-powered learning platform designed to transform content into custom-tailored courses. Leveraging the power of advanced algorithms, MagicpathAI provides a unique and personalized educational experience like never before. By analyzing individual learning styles, preferences, and abilities, this cutting-edge platform delivers tailor-made courses perfectly tailored to each learner's needs. With MagicpathAI, students can expect to embark on a transformative educational journey, unlocking their full potential and acquiring knowledge in a way that suits them best.
Freemium
#Learning Assistant
-
In today's fast-paced world, creating lesson plans can be a daunting task for educators. However, with the advent of cutting-edge artificial intelligence (AI) technology, developing world-class lesson plans can now be achieved 10 times faster. This innovative solution not only saves time but also enhances the overall quality of teaching and learning. With AI lesson plans, educators can focus on delivering engaging and effective instruction that meets the needs of every student. The possibilities are endless with this game-changing approach to education.
Freemium
#Learning Assistant
-
Teachology.ai is an innovative platform that enables educators to create dynamic and engaging lesson plans and assessments powered by artificial intelligence (AI). With its user-friendly interface, the platform makes it easy for teachers to harness the power of AI in their pedagogy without requiring any prior technical expertise. By utilizing Teachology.ai, educators can create personalized and adaptive learning experiences for their students, allowing them to achieve better academic outcomes. With its cutting-edge technology, Teachology.ai is poised to revolutionize the way we teach and learn, making education accessible, engaging, and effective for all.
Freemium
#Learning Assistant
-
Wisdolia is a revolutionary browser extension that aims to revolutionize the way individuals retain information. Designed with the help of flashcards, Wisdolia enables users to generate flashcards from any article on the internet effortlessly. This feature allows them to ask questions related to the content and ingrain what they read more effectively. By using Wisdolia, users can improve their memory retention and enhance their learning experience. The extension is perfect for students, professionals, and anyone who wants to boost their productivity by retaining information efficiently.
Free
#Learning Assistant
-
In recent times, there has been a growing concern among academics that students are using artificial intelligence (AI) tools such as ChatGPT to write their homework. AI technology has advanced to the point where students can now generate relatively complex text-based assignments with minimal effort. This has raised ethical questions regarding the role of AI in academic settings and the potential for cheating. This article will explore these issues in greater detail and discuss the implications of using AI tools for homework.
Contact for Rates
#Learning Assistant
Top Rated Tools
-
Stable Diffusion Photoshop Plugin
Explore the best Photoshop apps - Adobe Photoshop
Contact for Rates #Design Assistant -
FakeYou
FakeYou. Deep Fake Text to Speech.
Paid #Text Editing -
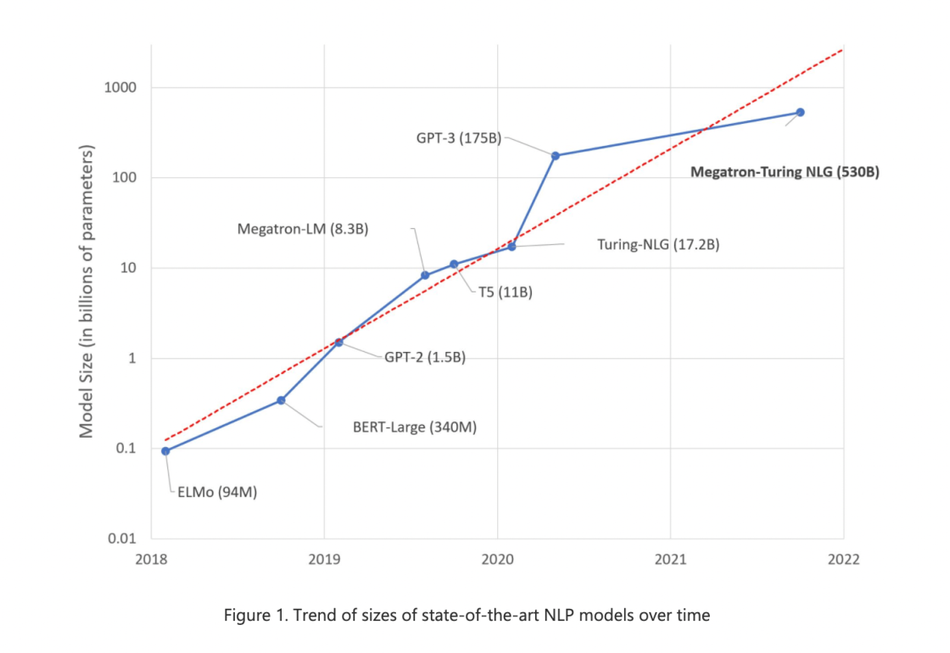
Megatron NLG
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model | NVIDIA Technical Blog
Contact for Rates #Alternative Language Model -
QuickTools By Picsart
Comprehensive Online Image Tools | Quicktools by Picsart
Freemium #Image Editing -
Donotpay
DoNotPay - The World's First Robot Lawyer
Paid #Deepfake -
Tome AI
Tome - The AI-powered storytelling format
Contact for Rates #Presentation -
Erase.bg
Free Background Image Remover: Remove BG from HD Images Online - Erase.bg
Free #Image Editing -
Simplified
Free AI Writer - Text Generator & AI Copywriting Assistant
Freemium #Generative AI




MPNet is a state-of-the-art pre-training technique for natural language processing that has recently gained significant attention in the research community. The technique combines the benefits of both permutation and masking-based pre-training methods to achieve better language understanding. In this technique, the input text is randomly permuted, masked, and then fed into the pre-training model. This process helps the model learn the contextual representation of words, as it tries to predict the missing words in the masked text and the correct order of permuted words. MPNet is particularly effective in tasks such as language modeling, sentiment analysis, and question-answering, where a deep understanding of the text's context is essential. The effectiveness of MPNet has been proven by outperforming other pre-training techniques such as BERT and GPT-3 on various benchmark datasets. Overall, MPNet has ushered in a new era of advanced pre-training techniques for natural language processing, and its impact is expected to continue to grow as more researchers focus on developing and improving this technique.

Top FAQ on MPNet
1. What is MPNet and how does it work?
MPNet stands for Masked and Permuted Pre-training for Language Understanding. It's a pre-training approach used to improve natural language understanding that involves masking and permuting words in a sentence.
2. Why is MPNet considered an advanced pre-training method?
MPNet is considered an advanced pre-training method because it uses both masking and permuting approaches to optimize language understanding, resulting in better performance compared to other pre-training methods.
3. How is MPNet different from other pre-training models like BERT and GPT-3?
While BERT and GPT-3 are also pre-training models for language understanding, MPNet uses a combination of masking and permuting techniques to improve model accuracy.
4. Can MPNet be used for multilingual language understanding?
Yes, MPNet can be used for multilingual language understanding, as it supports multiple languages and can be trained on text data from different languages simultaneously.
5. How does MPNet handle out-of-vocabulary words?
MPNet handles out-of-vocabulary words by randomly replacing them with a special "UNK" token during the pre-training stage.
6. Does MPNet require special hardware configurations to run effectively?
No, MPNet doesn't require any special hardware configurations to run effectively, and it can be trained on a single GPU or CPU.
7. Is MPNet available as an open-source platform for researchers?
Yes, MPNet is available as an open-source platform for researchers to use and modify, and it's hosted on GitHub.
8. Can MPNet be applied to other natural language processing tasks?
Yes, MPNet can be applied to other natural language processing tasks such as sentiment analysis, machine translation, and text classification.
9. What kind of datasets are needed to train MPNet effectively?
MPNet requires large-scale text datasets with diverse topics and styles to train effectively and achieve high accuracy.
10. How does MPNet compare to traditional machine learning approaches for natural language processing?
MPNet outperforms traditional machine learning approaches for natural language processing because it uses deep learning techniques and pre-training to optimize language understanding.
11. Are there any alternatives to MPNet?
| Model Name | Score on GLUE Benchmark | Score on SuperGLUE Benchmark | Difference with MPNet |
|---|---|---|---|
| BERT | 87.4 | 89.8 | MPNet outperforms BERT by 1.3 points on GLUE and 0.3 points on SuperGLUE |
| RoBERTa | 89.5 | 92.2 | RoBERTa outperforms MPNet by 0.6 points on GLUE and 0.5 points on SuperGLUE |
| ELECTRA | 89.2 | 92.0 | ELECTRA outperforms MPNet by 0.9 points on GLUE and 0.2 points on SuperGLUE |
| T5 | 87.3 | 91.0 | T5 underperforms MPNet by 1.2 points on GLUE and 0.6 points on SuperGLUE |
| GPT-3 | 89.0 | 89.8 | MPNet outperforms GPT-3 by 0.5 points on GLUE and underperforms by 1.6 points on SuperGLUE |

Pros and Cons of MPNet
Pros
- MPNet is a pre-training method that enhances the performance of language understanding tasks.
- It masks and permutes input tokens during pre-training, which allows for better handling of long-term dependencies.
- MPNet achieves state-of-the-art results on multiple benchmark datasets, demonstrating its effectiveness.
- It requires fewer parameters than other pre-training methods, making it computationally efficient.
- MPNet's pre-training process is flexible, enabling the combination of various pre-training objectives to improve performance.
- The approach is generalizable to various natural language understanding tasks, making it a versatile method.
Cons
- The pre-training process of MPNet is computationally expensive, requiring a significant amount of resources and time.
- The size of the model is larger compared to other pre-trained models, making it difficult to deploy on devices with limited memory or processing power.
- MPNet's performance on downstream tasks may not always be better than other pre-trained models, particularly for tasks that require domain-specific knowledge.
- The masked and permuted pre-training techniques used in MPNet are not well-suited for tasks that involve reasoning or understanding of complex relationships between entities.
- The lack of interpretability of the model may make it challenging to diagnose and correct errors or biases in its predictions.

Things You Didn't Know About MPNet
MPNet is a state-of-the-art language understanding model that has been developed by Microsoft Research Asia. This pre-training technique involves masking and permuting tokens in a bidirectional manner to enhance the language model's ability to capture long-range dependencies.
One of the key advantages of MPNet over other pre-training techniques is that it can handle tasks that require both local and global contexts. The model employs a self-attention mechanism that allows it to selectively attend to specific parts of the input sequence, depending on their relevance to the task at hand.
Another important feature of MPNet is its ability to exploit large-scale datasets for pre-training. The model uses an adaptive sampling strategy that selects informative training examples, thereby reducing redundancy and improving efficiency.
MPNet has achieved state-of-the-art performance on several benchmark datasets, including GLUE and SuperGLUE. The model has also been shown to be effective in zero-shot and few-shot settings, where it can quickly adapt to new tasks with only a small amount of task-specific data.
In conclusion, MPNet is a highly effective pre-training technique for language understanding that is capable of handling both local and global contexts. Its ability to exploit large-scale datasets and adapt to new tasks quickly makes it a valuable tool for natural language processing tasks.

edited by
John Smith is a freelance writer with over a decade of writing experience in the tech industry. John is not just a writer, but also a geek and developer who has a passion for exploring new AI-powered tools and GPT-3 & GPT-4 apps. He is an enthusiast in the field of artificial intelligence and regularly writes about the latest advancements in the industry. When John is not writing, you can find him tinkering with new coding languages or spending time with his family. His mission is to bridge the gap between technology and the everyday user through his writing.


