 New
New
 Free
Free
 Home
Home


Spark SQL is a powerful distributed query engine that has revolutionized the way structured data is handled. It provides a simple and efficient way to process structured data in a distributed environment. Spark SQL is designed to work seamlessly with other components of the Apache Spark ecosystem, making it an ideal choice for big data processing. This innovative technology enables organizations to perform complex analytics on large datasets in real-time, leading to better decision-making and improved business outcomes. In this article, we will explore the capabilities of Spark SQL and how it can be used to enhance data processing and analysis.
Usage: Data
Pricing: Free - Free
Tags: real-time decision-making structured data improved business outcomes distributed query engine
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots
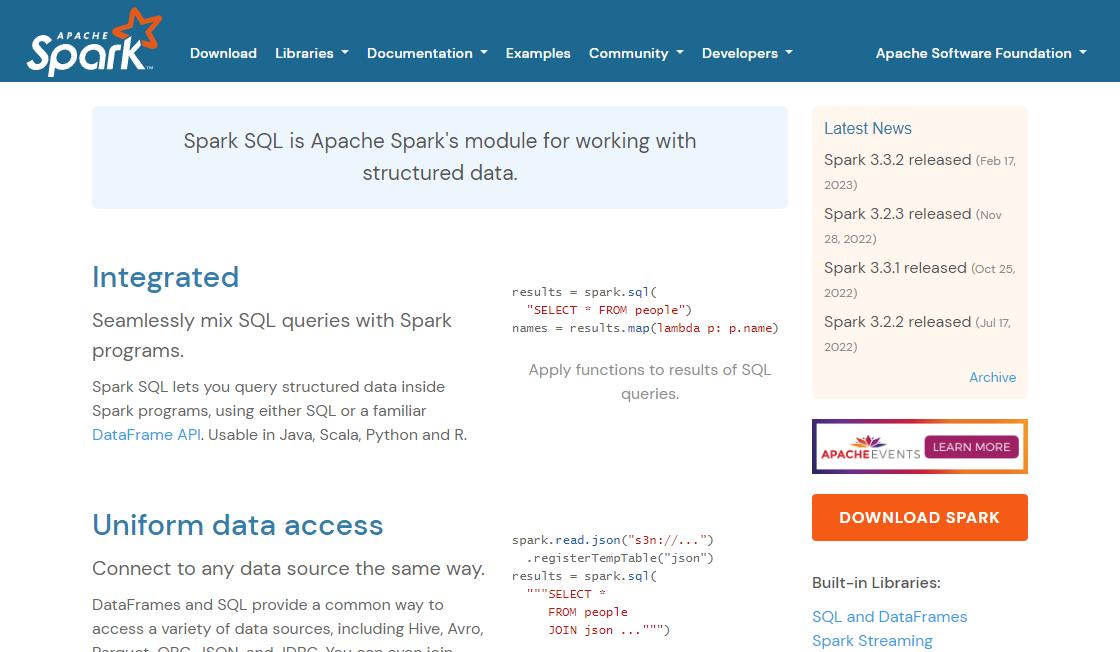
Video Reviews
Similar Tools to Spark SQL
-
Hi everyone, I am so glad to have finally launched this first of its kind template that lets you track crypto prices right inside your notion -> Link the prices database to as many templates as you want -> Syncs every 30 minutes -> 5 minutes to setup
 Contact for Rates
#Database
Contact for Rates
#Database
-
Journalist Hunt is a database of 340K+ journalists to help your business get media coverage. Our journalists are filtered by location, industry, tags, beats and outlets so you can quickly find ones who are best fit with your business.
Contact for Rates
#Database
-
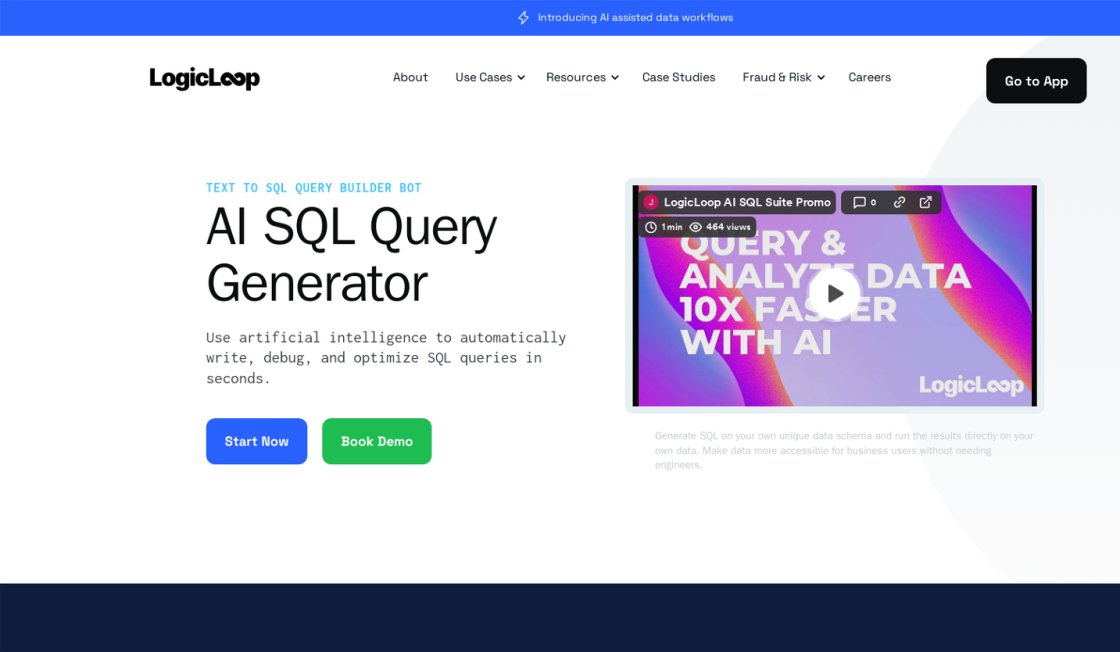
Logic Loop - AI SQL is a revolutionary tool that leverages the power of artificial intelligence to assist data analysts, engineers, and other data-related professionals in generating accurate and optimized SQL queries. With its advanced capabilities, Logic Loop - AI SQL can not only write, but also debug and edit complex SQL queries, making the data analysis process faster and more efficient. Powered by ChatGPT 4 and OpenAI, this cutting-edge solution provides an innovative way for businesses to streamline their data querying processes and extract valuable insights from their datasets.
Contact for Rates
#Database
-
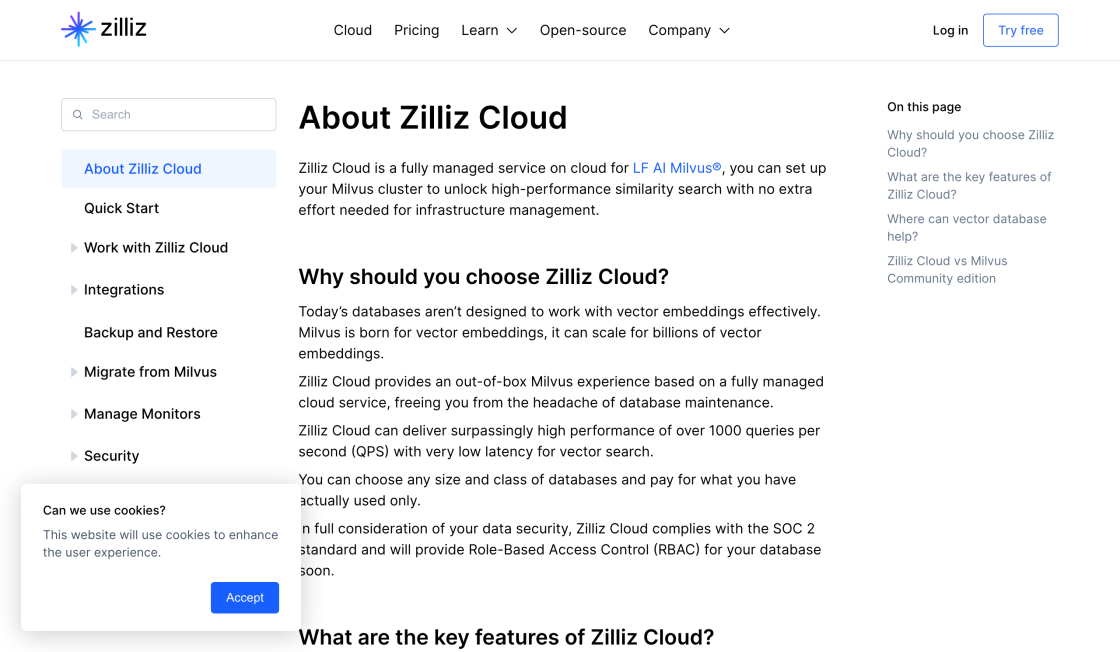
The Zilliz vector database management system, powered by Milvus, has emerged as a trusted platform for enterprise-grade vector search. With its ability to support billion-scale vector search and a client base comprising over 1,000 trusted enterprise users, Zilliz offers an innovative approach to data management and search functionality. This technology enables businesses to harness the power of vectors in a way that is scalable, efficient and cost-effective. As an emerging leader in the field of vector database management systems, Zilliz provides a reliable and comprehensive solution that can help companies of all sizes streamline their data processes and achieve their business objectives.
Contact for Rates
#Database
-
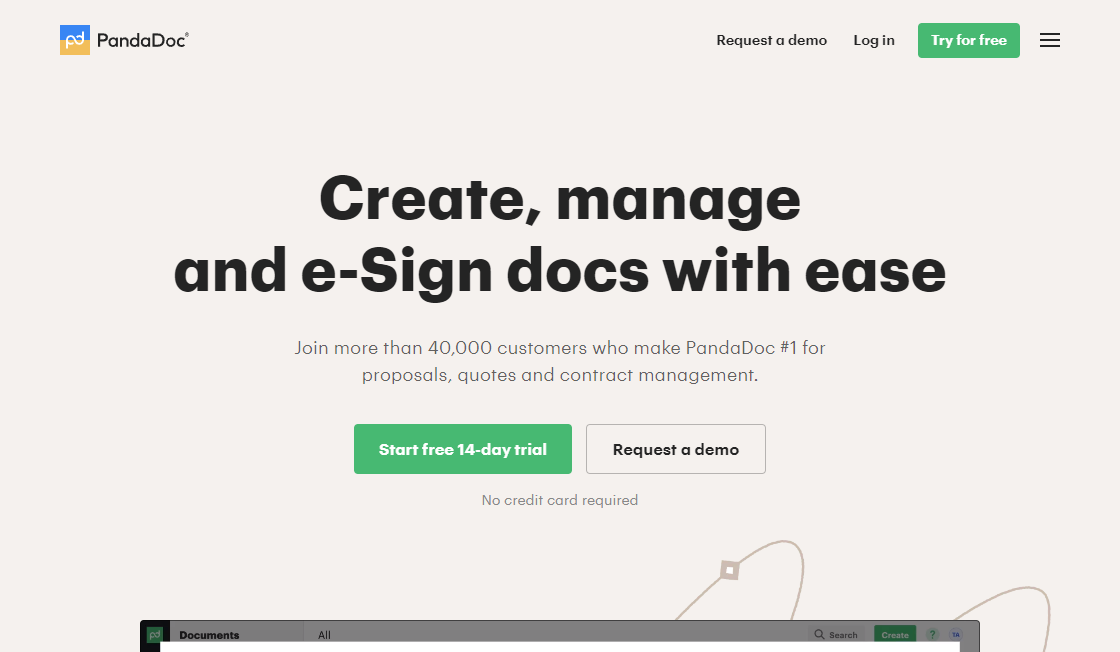
PandaDoc is a cutting-edge document automation software that offers advanced features such as cloud storage, eSignature, and analytics. This software solution is designed to streamline document creation, management, and collaboration, making it an ideal choice for businesses of all sizes. With PandaDoc, users can easily automate their document workflows, track document status, and improve their overall productivity. Whether you need to create proposals, contracts, or invoices, PandaDoc has got you covered with its user-friendly interface and robust functionality. In this article, we will explore the key features and benefits of PandaDoc and how it can help your business grow.
Paid
#Database
-
Dremio is a cutting-edge open-source data lake platform that provides a secure and efficient way to access and analyze data from various sources. With Dremio, users can seamlessly connect to different data sources, including cloud storage, databases, and Hadoop clusters, and perform complex queries without needing to move or transform data. This innovative platform is designed to empower businesses with the agility and flexibility they need to make informed decisions based on real-time insights gleaned from their data. In this article, we will explore the key features of Dremio and how it can help organizations unlock the full potential of their data.
Contact for Rates
#Database


Top Rated Tools
-
Remove.bg
Remove Background from Image for Free – remove.bg
Paid #Image Editing -
Grammarly
Grammarly: Free Online Writing Assistant
Free #Others -
AI Time Machine
AI Time Machine™ : créez des avatars IA et voyagez dans le temps
Freemium #Avatar Generation -
Craiyon
Craiyon, AI Image Generator
Free #Generative AI -
Copy.ai
Copy.ai: Write better marketing copy and content with AI
Paid #Others -
GPT-3 Recipe Builder
Generating Cooking Recipes with OpenAI's GPT-3 and Ruby
Contact for Rates #Others -
Klaviyo SMS Assistant
SMS Assistant AI Text Messages | Klaviyo Product Features
Paid #Sales Assistant -
WatermarkRemover.io
Watermark Remover - Remove Watermarks Online from Images for Free
Freemium #Image Editing



Spark SQL is a powerful tool that enables users to process and analyze large volumes of structured data in a distributed computing environment. It is a distributed query engine designed to work seamlessly with Apache Spark, the open-source big data processing framework. With Spark SQL, users can easily manipulate structured data using familiar SQL queries, making it an accessible and efficient option for data analysts and engineers. The engine supports a wide range of data sources, including Hive tables, Parquet files, and JSON data. Additionally, Spark SQL offers advanced features such as window functions, user-defined functions (UDFs), and support for machine learning libraries. By harnessing the power of Spark SQL, organizations can easily process and analyze structured data at scale, enabling them to make informed business decisions quickly and effectively. Overall, Spark SQL is a versatile and valuable tool for anyone working with structured data in a distributed computing environment.

Top FAQ on Spark SQL
1. What is Spark SQL?
Spark SQL is a distributed query engine that allows you to work with structured data in Apache Spark.
2. What kind of data can I work with using Spark SQL?
You can work with structured data, which includes data stored in tables or dataframes, CSV files, JSON files, and Parquet files.
3. Is Spark SQL compatible with all programming languages?
Yes, Spark SQL is compatible with all programming languages that work with Apache Spark, including Java, Python, R, and Scala.
4. How does Spark SQL distribute queries?
Spark SQL distributes queries across a cluster of machines using a distributed processing framework called Apache Spark.
5. Can I use Spark SQL for real-time data processing?
Yes, Spark SQL supports both batch and real-time data processing, making it a powerful tool for big data analytics.
6. How does Spark SQL handle large datasets?
Spark SQL is designed to handle large datasets by distributing the processing of data across a cluster of machines.
7. Can Spark SQL be used for machine learning?
Yes, Spark SQL can be used for machine learning tasks such as classification, clustering, and regression analysis.
8. What are the benefits of using Spark SQL?
Some of the benefits of using Spark SQL include faster data processing times, efficient handling of large datasets, and support for a wide range of data formats.
9. Is Spark SQL easy to learn?
For those familiar with SQL, Spark SQL can be relatively easy to learn. However, learning how to work with distributed systems and Apache Spark may take some time.
10. Can Spark SQL be used for data visualization?
While Spark SQL is primarily a query engine, it can be used in conjunction with data visualization tools such as Tableau to create compelling visualizations of big data.
11. Are there any alternatives to Spark SQL?
| Competitor | Description | Difference from Spark SQL |
|---|---|---|
| Apache Hive | A data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. | Hive uses a SQL-like language called HiveQL, while Spark SQL supports both SQL and programming languages like Java, Scala, and Python. |
| Amazon Redshift | A cloud-based data warehousing service that makes it simple and cost-effective to analyze all your data using standard SQL and existing Business Intelligence (BI) tools. | Redshift is a fully-managed service, while Spark SQL requires more manual configuration and setup. |
| Google BigQuery | A fully-managed cloud data warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure. | BigQuery is optimized for large-scale data warehousing, while Spark SQL is designed for working with structured data across distributed systems. |
| Microsoft Azure SQL Data Warehouse | A cloud-based enterprise data warehouse that leverages massive parallel processing (MPP) to quickly run complex queries across petabytes of data. | Azure SQL DW is integrated with other Azure services, while Spark SQL is part of the Apache Spark ecosystem and can be used on various cloud platforms. |
| Snowflake | A cloud-based data warehousing platform that provides a SQL interface and supports both structured and semi-structured data. | Snowflake offers automatic scaling and multi-cluster support, while Spark SQL requires more manual tuning for performance optimization. |

Pros and Cons of Spark SQL
Pros
- Handles structured data: Spark SQL is designed to work with structured data, which makes it easier to manage and analyze large datasets.
- Distributed query engine: This means that Spark SQL can process queries across multiple nodes, which allows for faster processing and better scalability.
- Supports SQL queries: Spark SQL supports SQL queries, which makes it familiar to those who are already experienced with SQL.
- Integration with Spark ecosystem: Spark SQL integrates seamlessly with other Spark components, such as Spark Streaming and MLlib, which allows for easy analysis and machine learning on structured data.
- Wide range of data sources: Spark SQL supports a wide range of data sources, including Hive tables, Parquet files, and JDBC data sources.
- In-memory caching: Spark SQL has the ability to cache data in memory, which can greatly improve query performance.
Cons
- Requires knowledge of SQL language to operate effectively
- Can be difficult to handle for beginners or those inexperienced with big data analysis
- Might require additional hardware and software investments to support distributed query engine
- Performance may suffer if not properly configured or optimized
- Limited support for some data formats or sources compared to other big data tools
- May not be the best option for unstructured or semi-structured data
- Can be expensive for small businesses or startups to implement and maintain.

Things You Didn't Know About Spark SQL
Spark SQL is a powerful distributed query engine that has revolutionized the way structured data is processed. It is an efficient tool for those who work with large datasets and want to analyze them accurately and quickly. Here are some things you should know about Spark SQL:
1. Distributed Query Engine: Spark SQL is a distributed query engine that is designed to process large volumes of data by distributing queries across a cluster of machines. This makes it an ideal choice for big data processing.
2. Structured Data: Spark SQL is primarily designed to work with structured data, which means data that is organized into tables or columns. It supports popular data formats such as CSV, JSON, ORC, and Parquet.
3. SQL Support: Spark SQL provides a SQL interface that allows users to write SQL queries to manipulate data. It also supports a wide range of SQL functions such as aggregation, filtering, sorting, and joining.
4. Integration with Spark: Spark SQL is built on top of Apache Spark, which means it integrates seamlessly with other Spark components such as Spark Streaming, MLlib, and GraphX.
5. Performance: Spark SQL is highly optimized for performance and can process data much faster than traditional SQL engines. It achieves this by using in-memory caching and optimized query execution plans.
6. Machine Learning: Spark SQL has built-in support for machine learning algorithms, which means it can be used for predictive analytics and data science tasks.
7. Open Source: Spark SQL is an open-source project, which means it is available for anyone to use and contribute to. This ensures that it remains up-to-date and innovative.
In conclusion, Spark SQL is a powerful distributed query engine that is designed to work with structured data. It provides a SQL interface, integrates seamlessly with other Spark components, and is highly optimized for performance. It is an excellent choice for anyone who works with big data and wants to analyze it quickly and accurately.

edited by
Emily Collins is a freelance writer with over a decade of experience in the field. Emily has a passion for all things tech, especially AI-powered tools and GPT-3 & GPT-4 apps. She is a self-proclaimed geek and developer, always looking for the latest and greatest in software and coding. When she's not writing, Emily can usually be found tinkering with her computer, playing video games, or reading science fiction novels. With her unique combination of writing skills and tech expertise, Emily is a valuable asset to any project she takes on.


