 New
New
 Free
Free
 Home
Home


Speech-to-Speech - Resemble AI's Real-time Speech-to-Speech Voice Conversion is a cutting-edge technology that allows users to transform their voices into another person's or character's voice in real-time. This AI voice generator uses advanced deep learning and natural language processing techniques to produce high-quality voice conversion within seconds. With its innovative features, this technology is reshaping the way we communicate and interact with each other, making it easier for individuals to express themselves with more creativity and authenticity.
Usage: Writing
Pricing: Paid - From $0.006/second
Tags: natural language processing creativity communication real-time high-quality
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots
Video Reviews
Similar Tools to Speech-to-Speech
-
After the Deadline is a revolutionary AI-assisted tool that aims to enhance the writing process by providing writers with accurate grammar, spelling and style suggestions. This innovative technology has been designed to help individuals improve their writing skills and produce high-quality content more efficiently. With its advanced algorithms and machine learning capabilities, After the Deadline is able to identify errors and inconsistencies in writing, and suggest corrections that can significantly enhance the overall quality of any written piece. Whether you are a student, a professional writer, or simply someone who wants to improve their writing skills, After the Deadline is an essential tool that can help you achieve your goals.
 Free
#Text Editing
Free
#Text Editing
-
Atom Editor is a powerful and versatile text editor designed to help developers write code with ease and precision. Powered by web technologies, this hackable editor offers a range of features that make coding faster, more efficient, and more enjoyable. With its intuitive interface, customizable layout, and extensive library of plugins, Atom Editor has become a go-to tool for developers worldwide. Whether you're a seasoned programmer or just starting out, Atom Editor is a must-have tool for anyone serious about coding.
Free
#Text Editing
-
Grammar AI is a revolutionary digital assistant designed to help individuals in detecting grammatical, spelling, and style errors in their writing. Powered by AI technology, it is the perfect tool for anyone looking to improve their writing skills and produce error-free content. Grammar AI provides precise and quick feedback that enables writers to identify and correct mistakes before submitting their work. This digital assistant is an essential tool for professionals, students, and anyone seeking to improve their writing.
Contact for Rates
#Text Editing
-
ReadSpeaker AI is a leading voice innovation company that specializes in providing custom digital voices to brands, agencies, and developers. With their range of solutions, including custom Text-To-Speech (TTS) voices, voice cloning software, and a vast library of TTS voices in over 35 languages, ReadSpeaker AI enhances digital interactions for customers across multiple touchpoints. Their advanced technology enables lifelike digital experiences for users, making them a top choice in the industry.
Contact for Rates
#Text Editing
-
Big Speak is a revolutionary AI software that has changed the game for text-to-speech conversion. With its advanced machine learning algorithms, Big Speak lets users generate audio from text in multiple languages. The software produces high-quality voice clips that sound incredibly realistic, making it an essential tool for content creators, podcasters, and businesses alike. What's more, Big Speak is entirely free, making it accessible to everyone who wants to add spoken content to their projects. In this article, we will explore the benefits of using Big Speak and how it can help you take your content to the next level.
Free
#Text Editing
-
Stable diffusion is a powerful text-to-image model that enables the generation of photo-realistic images. It is based on an algorithmic process which can generate high-fidelity visual representations of semantic concepts described by natural language. By using stable diffusion, computers can now be used to accurately and efficiently create realistic images from text descriptions. This technology has the potential to revolutionize the way we create and interact with visual media.
Free
#Generative AI


Top Rated Tools
-
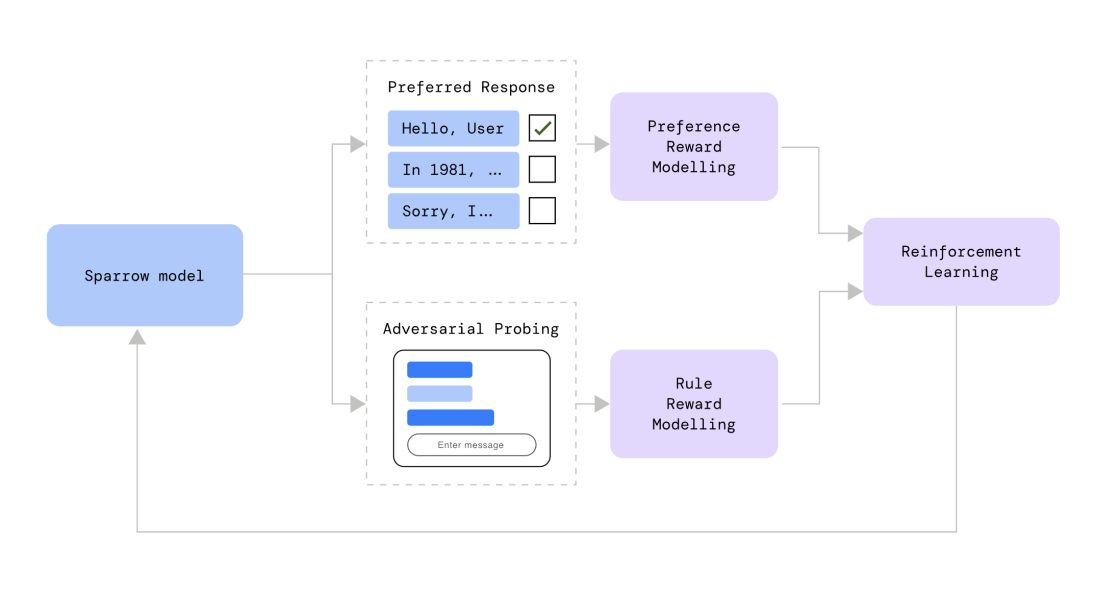
Deepmind Sparrow AI
[2209.14375] Improving alignment of dialogue agents via targeted human judgements
Contact for Rates #Chatbot -
QuickBooks
QuickBooks®: Official Site | Smart Tools. Better Business.
Contact for Rates #Others -
Neural.Love
Free AI Image Generator & AI Enhance | neural.love
Contact for Rates #Generative AI -
Runway ML
Runway - Everything you need to make anything you want.
Contact for Rates #Text Editing -
Uberduck
Uberduck | Text-to-speech, voice automation, synthetic media
Paid #Text Editing -
Tome
The Future of Content Management
Free #Generative AI -
Unbounce
Smart Copy: AI Copywriting & Content Generator Tool | Unbounce
Paid #Writing Assistant -
Nijijourney
NijiJourney AI for the anime fans. The new niji model is tuned with a fine eye to produce anime and illustrative styles. It has vastly more knowledge of anime, anime styles, and anime aesthetics. It's great at dynamic and action shots, and character-focused compositions in general.
Free Trial #Generative AI

Speech-to-speech technology has come a long way since its inception, and the latest innovation in this field is Resemble AI's Real-time Speech-to-Speech Voice Conversion. This revolutionary AI voice generator allows users to transform their voice into another in a matter of seconds. Leveraging the power of deep learning and natural language processing, Resemble AI has created a state-of-the-art tool that offers high-quality voice conversion in real-time.
With this cutting-edge technology at their disposal, users can now create engaging content that captivates their audience without the need for professional voice artists. Resemble AI's Real-time Speech-to-Speech Voice Conversion has numerous applications, ranging from entertainment and gaming to healthcare and education. It enables users to add a personal touch to their content and improve the user experience by providing a more engaging and interactive interface.
This technology is set to revolutionize the way we communicate and interact with each other, making it easier for people to connect and collaborate across different languages and cultures. As we move towards a more globalized world, Resemble AI's Real-time Speech-to-Speech Voice Conversion will play a crucial role in breaking down language barriers and fostering greater understanding and collaboration among people.

Top FAQ on Speech-to-Speech
1. What is Speech-to-Speech by Resemble AI?
Speech-to-Speech is an AI-powered voice generator developed by Resemble AI that can transform one's voice into another in real-time.
2. How does Speech-to-Speech work?
Speech-to-Speech uses deep learning and natural language processing to analyze the input voice and convert it into the desired output voice within seconds.
3. Can I use Speech-to-Speech for professional purposes?
Yes, Speech-to-Speech can be used for professional purposes like creating voiceovers, audio books, and podcasts with high-quality voice conversion.
4. Is Speech-to-Speech easy to use?
Yes, Speech-to-Speech is user-friendly and requires no technical knowledge to use. It has a simple interface that anyone can use to generate voices.
5. How accurate is the voice conversion process in Speech-to-Speech?
The voice conversion process in Speech-to-Speech is highly accurate and produces high-quality output voices that resemble the target voice.
6. Can I customize the output voice generated by Speech-to-Speech?
Yes, Speech-to-Speech provides customization options to adjust the pitch, tone, and speed of the output voice to match the desired voice.
7. Is Speech-to-Speech available in multiple languages?
Yes, Speech-to-Speech supports multiple languages including English, Spanish, French, German, Italian, and Japanese.
8. What are the system requirements for using Speech-to-Speech?
Speech-to-Speech is a web-based application that works on any device with a stable internet connection and a modern web browser.
9. Is my data secure while using Speech-to-Speech?
Yes, Resemble AI uses advanced security measures to protect user data and ensure privacy during the voice conversion process.
10. How much does Speech-to-Speech cost?
Speech-to-Speech offers flexible pricing plans based on usage and customization options, starting from $10 per month.
11. Are there any alternatives to Speech-to-Speech?
| Competitor | Description | Key Features | Difference |
|---|---|---|---|
| Google Cloud Text-to-Speech | Google's AI-powered text-to-speech service that converts written text into natural-sounding speech in a variety of languages and voices | Supports multiple languages and voices, customizable intonation and pitch, integration with other Google services | Focuses on text-to-speech conversion rather than speech-to-speech conversion. |
| Lyrebird | A voice synthesis platform that allows users to create digital voice clones of themselves or others by analyzing just a few minutes of audio recordings | High-quality voice cloning, supports multiple languages and accents, customizable voice parameters | Does not offer real-time voice conversion. |
| Modulate | An AI-powered voice modulation platform that lets users alter their voice in real-time during live voice and video calls | Real-time voice modulation, supports multiple voice effects, works with popular communication apps like Zoom and Discord | Focuses on voice modulation rather than voice conversion. |
| TalkMeUp | A speech analytics and voice coaching platform that helps users improve their speaking skills by analyzing their speech patterns and providing feedback | Real-time speech analysis and feedback, supports multiple languages, customizable coaching plans | Not focused on voice conversion or synthesis. |

Pros and Cons of Speech-to-Speech
Pros
- Enables real-time voice conversion
- Uses deep learning and natural language processing for high quality conversion
- Provides a fast and efficient way of transforming one's voice into another
- Can be used for entertainment purposes, such as creating voiceovers or impersonations
- Has potential use in industries such as gaming, film, and animation
- Offers a unique and innovative technology that sets it apart from other voice conversion tools.
Cons
- May not accurately capture the nuances and subtleties of the original voice
- Can potentially be used for fraudulent purposes, such as impersonation
- Could lead to privacy concerns if used to create false recordings of individuals
- Reliance on technology could lead to over-reliance and loss of authentic communication skills
- May not be accessible or effective for individuals with speech disorders or accents
- Possible ethical concerns regarding the use of AI to manipulate or alter human communication.

Things You Didn't Know About Speech-to-Speech
Speech-to-Speech - Resemble AI's Real-time Speech-to-Speech Voice Conversion is an innovative technology that allows users to transform their voice into another person's voice in real-time. This AI voice generator is a game-changer in the field of voice conversion as it leverages deep learning and natural language processing for high-quality voice conversion.
One of the most remarkable features of Speech-to-Speech is its ability to convert voices in real-time. This means that users can speak into the system, and the transformed voice will be generated in seconds. The technology behind this process is based on deep learning algorithms that analyze the user's voice and convert it into the desired voice seamlessly.
The AI-powered technology used in Speech-to-Speech ensures that the output voice is of high quality and resembles the target voice accurately. This is made possible by the system's ability to understand the nuances of human speech, including intonation, pitch, and tone. With Speech-to-Speech, users can create a wide range of voices, from celebrity impressions to fictional characters.
Moreover, Speech-to-Speech offers a user-friendly interface that makes it easy for anyone to use, regardless of their technical expertise. The system comes with a variety of pre-built models that users can choose from, or they can create their own custom models using the platform's training data.
In conclusion, Speech-to-Speech - Resemble AI's Real-time Speech-to-Speech Voice Conversion is a cutting-edge technology that offers endless possibilities for voice transformation. It is perfect for content creators, voice actors, and anyone who wants to have fun with voice conversion. With its advanced deep learning algorithms and natural language processing, Speech-to-Speech promises to revolutionize the world of voice conversion.

edited by
Samantha Lee is a freelance writer with over a decade of experience writing for a variety of industries. She is an avid enthusiast of AI powered tools and GPT-3 & GPT-4 apps, constantly exploring new ways to incorporate these technologies into her work. As a self-proclaimed geek, Samantha spends her free time diving deep into the latest tech gadgets and coding projects. Her writing has been featured in numerous publications and she has won several writing awards. When she's not writing or coding, you can find Samantha hiking or exploring new restaurants in her hometown of San Francisco.


