 New
New
 Free
Free
 Home
Home

SSD, also known as Single Shot MultiBox Detector, is a highly effective deep learning object detection framework. It uses advanced algorithms and techniques to identify objects in images with remarkable accuracy. The SSD framework has proven to be a game-changer in the field of computer vision, enabling machines to recognize and classify objects in real-time. Its ability to perform object detection quickly and accurately makes it a popular choice for a wide range of applications, including autonomous vehicles, security systems, and medical imaging. In this article, we will explore the features and benefits of the SSD framework in detail.
Usage: Other
Model: GitHub
Pricing: Contact for Rates - Open Source
Tags: algorithms real-time deep learning computer vision object detection
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts | Contact Info


Product Screenshots
Video Reviews
Similar Tools to SSD
-
Navan.ai is a platform enabling developers and businesses to build and deploy computer vision AI models without writing a single line of code in minutes while saving upto 85% of the development time and cost. Nstudio.navan.ai allows you to build computer vision models in minutes without any coding. Ncloud.navan.ai allows you to deploy AI models on the cloud and get an inference API in less than a minute. You can also choose to use pre-trained Vision AI models like person detection and more.
 Contact for Rates
#Computer Vision
Contact for Rates
#Computer Vision
-
Playment is an innovative web platform that aims to support users in constructing robust computer vision pipelines for efficient digital asset management. This cutting-edge technology assists organizations in streamlining their workflows by automating the process of image and video analysis. The platform's advanced algorithms enable accurate object recognition, classification, and tagging, making it an indispensable tool for businesses that rely heavily on visual content. With Playment, users can leverage the power of computer vision to improve their productivity, reduce costs, and enhance the quality of their digital assets.
Paid
#Computer Vision
-
TensorFlow Lite is a cutting-edge deep learning framework specially designed for on-device inference. This open-source framework enables developers to create highly efficient and optimized machine learning models that can be deployed on mobile and embedded devices. With TensorFlow Lite, developers can leverage the power of machine learning capabilities on small devices such as smartphones, IoT devices, and other edge devices. TensorFlow Lite is built on top of Google's TensorFlow machine learning library, making it one of the most reliable and robust frameworks for on-device machine learning inference.
Free
#Computer Vision
-
AWS DeepLens is a revolutionary tool for developers to explore and create deep learning computer vision applications. The integration of Amazon Web Services (AWS) makes it easy to build, train, and deploy machine learning models. This deep learning tool is an excellent resource for developers who want to explore the possibilities of artificial intelligence and machine learning in their applications. AWS DeepLens provides a comprehensive platform that enables developers to create and deploy cutting-edge computer vision applications with ease.
Contact for Rates
#Computer Vision
-
NeoVision is an innovative image and video recognition service that utilizes the power of artificial intelligence to deliver cutting-edge solutions to organizations. With its advanced algorithms, NeoVision can accurately identify and classify images and videos, making it an invaluable tool for businesses in a wide range of industries. Whether you're looking to improve your marketing campaigns, enhance your security systems, or streamline your operations, NeoVision has the expertise and technology to help you achieve your goals. Discover the power of AI-driven image and video recognition with NeoVision today.
Contact for Rates
#Computer Vision
-
OpenCV, or Open Source Computer Vision Library, is a powerful and widely-used open-source computer vision and machine learning software library. It was initially developed by Intel, but is now maintained and supported by a large community of developers around the world. OpenCV provides a vast range of tools and algorithms that allow developers to create advanced computer vision applications, including object detection, image segmentation, facial recognition, and more. Its accessibility and flexibility make it an essential tool for researchers, hobbyists, and professionals alike.
Free
#Computer Vision


Top Rated Tools
-
Remove.bg
Remove Background from Image for Free – remove.bg
Paid #Image Editing -
500+ Openers For Tinder Written By GPT-3
500+ Original Conversation Starters
Contact for Rates #Humor -
Alien Genesys
AI Powered DNA Analysis
Contact for Rates #Generative AI -
Google GShard
[2006.16668] GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Contact for Rates #Alternative Language Model -
Ghostwriter
Ghostwriter - Code faster with AI - Replit
Paid #Creative Writing -
Media.io
Media.io - Online Free Video Editor, Converter, Compressor
Contact for Rates #Image Editing -
Casetext
AI-Powered Legal Research
Free Trial #Legal Assistant -
Erase.bg
Free Background Image Remover: Remove BG from HD Images Online - Erase.bg
Free #Image Editing


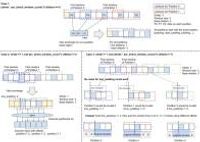

SSD or Single Shot MultiBox Detector is a state-of-the-art deep learning object detection framework that has revolutionized the field of computer vision. The framework is designed to detect objects of various sizes and shapes in images and videos with high accuracy and efficiency. As compared to traditional object detection methods that rely on region proposal algorithms, SSD uses a single neural network to predict object classes and locations directly from input images. This makes it faster and more efficient than other object detection frameworks, making it ideal for real-time applications such as self-driving cars, surveillance systems, and robotics. SSD achieves this by using a multi-scale feature extraction approach that captures objects at different scales and resolutions, allowing it to detect objects of varying sizes, orientations, and deformations. With its robust performance, ease of use, and versatility, SSD has become a popular choice among researchers and developers working on computer vision projects.

Top FAQ on SSD
1. What is SSD?
SSD stands for Single Shot MultiBox Detector, which is a deep learning object detection framework.
2. How does SSD work?
SSD uses deep convolutional neural networks to detect objects in images and videos.
3. What are the benefits of using SSD?
SSD is fast, accurate, and can detect multiple objects in a single shot.
4. What kind of objects can SSD detect?
SSD can detect a wide range of objects, including people, animals, vehicles, and other objects.
5. Is SSD suitable for real-time applications?
Yes, SSD is designed for real-time object detection and is widely used in applications such as autonomous driving and surveillance systems.
6. What programming languages are compatible with SSD?
SSD can be implemented using Python, C++, and other programming languages commonly used in deep learning.
7. How accurate is SSD in detecting objects?
SSD has achieved state-of-the-art performance in object detection benchmarks and is considered one of the most accurate object detection frameworks.
8. Can SSD detect objects in videos?
Yes, SSD can detect objects in both images and videos.
9. Is SSD an open-source framework?
Yes, SSD is an open-source framework and is available on GitHub.
10. What are some popular applications of SSD?
Some popular applications of SSD include self-driving cars, security cameras, and object recognition in robotics.
11. Are there any alternatives to SSD?
| Competitor | Difference from SSD |
|---|---|
| YOLO | Faster inference speed but lower accuracy compared to SSD |
| Faster R-CNN | Slower inference speed compared to SSD but higher accuracy |
| RetinaNet | Higher accuracy compared to SSD but slower inference speed |
| Mask R-CNN | Can detect and segment objects, while SSD can only detect |

Pros and Cons of SSD
Pros
- High accuracy in detecting objects
- Faster processing time compared to traditional object detection methods
- Can detect multiple objects in a single shot
- Can detect objects at different scales and aspect ratios
- Can be trained on large datasets for improved performance
- Can be used for various applications such as autonomous vehicles and surveillance systems
- Robust to occlusions and changes in lighting conditions
- Efficient memory usage compared to other deep learning object detection frameworks.
Cons
- Requires a large amount of data to train effectively
- Can be computationally expensive, requiring powerful hardware or cloud computing resources
- May not perform well in detecting small or heavily occluded objects
- Limited interpretability and difficulty in understanding how the model makes its predictions
- Requires expertise in deep learning and computer vision to implement and fine-tune effectively
- Limited generalization to new or unseen scenarios or objects
- Vulnerable to adversarial attacks and unintentional biases in the training data.

Things You Didn't Know About SSD
SSD (Single Shot MultiBox Detector) is an advanced deep learning object detection framework that has become increasingly popular in recent years. As its name suggests, SSD is designed to detect objects within images or videos in real-time with high accuracy.
One of the key features of SSD is its ability to perform object detection using a single neural network. This means that the entire process of detecting objects, from extracting features to predicting bounding boxes, can be done in one step. This not only makes the process faster but also more accurate than other object detection frameworks that require multiple steps.
Another advantage of SSD is that it is highly configurable, allowing users to customize the framework to suit their specific needs. It supports a wide range of input sizes and aspect ratios, making it ideal for use in a variety of applications, including autonomous driving, surveillance, and robotics.
One of the challenges in object detection is dealing with objects of different sizes and scales. SSD addresses this by using a multi-scale feature map approach, which allows it to detect objects of different sizes with similar accuracy. This is achieved by dividing the input image into multiple grids, each with a different scale, and then applying convolutional filters to extract features from each grid.
Overall, SSD is a powerful and versatile deep learning object detection framework that offers high accuracy and real-time performance. Its flexibility and configurability make it an ideal choice for a wide range of applications, and its ability to detect objects of different sizes and scales makes it a valuable tool in many industries.
Get in touch with SSD

edited by
Jack Richards is a self-proclaimed geek and AI enthusiast who has been freelancing as a writer for over a decade. With a rich writing experience in various niches, Jack's love for technology led him to explore the world of AI-powered tools and GPT-3 & GPT-4 apps. He has been fascinated with the possibilities that AI can bring to the writing world, and spends much of his time experimenting with different tools and software. Jack's passion for writing and technology has led him to create some of the most unique and thought-provoking content in his field, making him a recognized name among the writing community.


