 New
New
 Free
Free
 Home
Home


The Pile is an 800GB dataset of diverse text for language modeling. It includes a wide range of texts from literature, news, and web sources, making it one of the most comprehensive datasets for language modeling available. It is a great resource for language researchers and developers working on natural language processing (NLP) tasks such as machine translation, question answering, and other conversational applications.
Usage: Data
Pricing: Contact for Rates
Tags: developers NLP news resource literature
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts | Contact Info


Product Screenshots
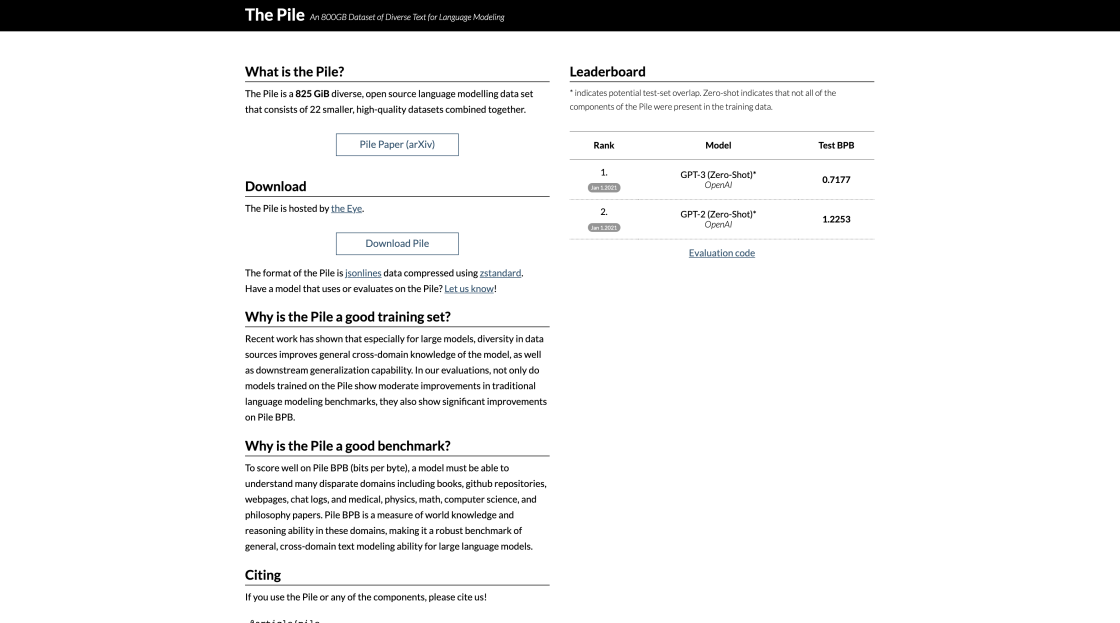
Video Reviews
Similar Tools to The Pile
-
At Kinsta, we make running projects of all sizes quick and seamless, with our Application Hosting, Database Hosting, Static Site Hosting, and Managed WordPress Hosting. Our hosting is for all types of projects, and we serve 55,000+ users from 128 countries around the globe.
 Contact for Rates
#Database
Contact for Rates
#Database
-
MySQL for Developers is a free 64 lesson video course that we created for developers who want to strengthen their MySQL and database skills in a way that’s relevant to their everyday work: application development.
Free
#Database
-
Flexberry AI Assistant is a cutting-edge solution that streamlines the requirement processing and artifact generation process for business analysts. This innovative tool, known as Flexberry, harnesses the power of artificial intelligence to automate and enhance various aspects of this critical workflow. By leveraging advanced algorithms and machine learning capabilities, Flexberry AI Assistant enables businesses to efficiently analyze and interpret complex requirements, resulting in accurate and tailored artifact generation. With its user-friendly interface and intelligent automation, Flexberry revolutionizes the way business analysts operate, increasing productivity and consistency while reducing the risk of errors.
Contact for Rates
#Database
-
Communion is an innovative tool designed to revolutionize the creative process for individuals and growing teams. Powered by AI and analytics, this web-based application offers a streamlined approach to content creation, enabling students, sales representatives, marketers, and professionals in any field to produce compelling content with ease and efficiency. With its user-friendly interface and advanced features, Communion is set to transform the way people work and innovate, empowering them to achieve their goals faster and more effectively than ever before.
Paid
#Database
-
Abacus.AI is an advanced AI platform that caters to a wide range of enterprises by offering a variety of AI tools. The platform provides a complete end-to-end solution for real-time machine and deep learning, empowering businesses with personalization, forecasting, planning, anomaly detection, NLP, fraud and security, language AI, and vision AI. With the ability to scale effortlessly, the technology provided by Abacus.AI has become an indispensable tool for many organizations that seek to leverage the benefits of AI in their operations.
Contact for Rates
#Database
-
Sumo Logic is a cloud-based logging and analytics platform that enables organizations to gain real-time insights into their infrastructure and applications. With its advanced machine learning algorithms and scalable architecture, Sumo Logic provides businesses with unparalleled visibility into their operations, helping them to troubleshoot issues, optimize performance, and improve security. The platform supports a wide range of log sources, including servers, containers, network devices, and cloud services, making it an ideal solution for modern, hybrid IT environments. By leveraging Sumo Logic, organizations can stay ahead of the curve and drive their digital transformation initiatives forward.
Contact for Rates
#Database

Top Rated Tools
-
Magic Write By Canva
The AI Powered Writing Tool
Contact for Rates #Writing Assistant -
Opera
Browser with Built-in VPN
Contact for Rates #Browser -
Repl.it
Replit: the collaborative browser based IDE - Replit
Free #Code Assistant -
Copy.ai
Copy.ai: Write better marketing copy and content with AI
Paid #Others -
Casetext
AI-Powered Legal Research
Free Trial #Legal Assistant -
WatermarkRemover.io
Watermark Remover - Remove Watermarks Online from Images for Free
Freemium #Image Editing -
TwitterBio
AI Twitter Bio Generator – Vercel
-
Uberduck
Uberduck | Text-to-speech, voice automation, synthetic media
Paid #Text Editing

The Pile is an 800GB dataset of diverse text for language modeling and natural language processing. It includes a vast range of texts from across the world, providing near limitless opportunities for researchers and developers to explore and develop new and interesting applications. The vastness of the dataset also means that it can be used to train large-scale language models, giving researchers the ability to create more accurate models.
The Pile dataset was built using a variety of sources, such as books, news articles, and blogs. This provides a comprehensive collection of text covering a wide range of topics, including science, history, politics, and culture. As a result, the dataset contains a wealth of information that can be used to develop powerful language models.
The Pile dataset is designed to be simple to use, offering easy access to the data via a number of APIs. Additionally, the dataset can be used in conjunction with other datasets for language modeling tasks, allowing for even more powerful models.
Overall, The Pile offers a great opportunity for researchers and developers to explore and develop applications related to natural language processing. With its vast size, the dataset provides plenty of information for developing large-scale language models, allowing for more accurate results.

Top FAQ on The Pile
2. How large is The Pile?
The Pile is 800GB in size.
3. What kind of text does The Pile contain?
The Pile contains a variety of text from different sources, including books, articles, and online conversations.
4. Is The Pile open-source?
Yes, The Pile is open-source and available to anyone who wishes to use it.
5. Are there any restrictions to using The Pile?
There are no restrictions to using The Pile, but it is recommended that you cite the source when using The Pile.
6. Where can I access The Pile?
The Pile is available online at its official website.
7. What types of language models can be trained with The Pile?
The Pile can be used to train a variety of language models, including recurrent neural networks, transformers, and other deep learning models.
8. Is there any support to help me use The Pile?
Yes, The Pile offers a range of support materials and tutorials to help users get started.
9. Does using The Pile require any special skills or knowledge?
No, The Pile is designed to be accessible to anyone, regardless of their level of expertise.
10. Does The Pile offer any data visualization tools?
Yes, The Pile offers a range of data visualization tools to help users explore the data and identify patterns.
11. Are there any alternatives to The Pile?
| Competitor | Difference |
|---|---|
| One Billion Word Benchmark | The Pile is a collection of diverse text from many sources, while the One Billion Word Benchmark is a collection of web crawled text. |
| English Wikipedia | The Pile is a collection of diverse text from many sources, while the English Wikipedia is a single source of text. |
| Common Crawl | The Pile is a collection of diverse text from many sources, while Common Crawl is a collection of web crawled text. |
| BooksCorpus | The Pile is a collection of diverse text from many sources, while BooksCorpus is a collection of books. |

Pros and Cons of The Pile
Pros
- It contains a large volume of data for training language models.
- The dataset is highly diverse and covers a wide range of topics.
- It is well-organized, with text divided into categories for easy searching.
- It is constantly updated, ensuring the most up-to-date information is available.
- It is free and open source, allowing anyone to use it for their language modeling needs.
Cons
- Too large of a dataset to be useful for general language modeling tasks
- Not enough examples of rare words and phrases
- Poor quality of data due to its unstructured format
- Difficulty in finding the correct subsets of data for specific tasks
- Limited access to the dataset for free users

Things You Didn't Know About The Pile
The Pile is an 800GB dataset of diverse text for language modeling. It was created by the Allen Institute for Artificial Intelligence (AI2) and contains a large collection of diverse text data from sources such as books, Wikipedia, and webpages. The dataset was developed to help machine learning models better understand and learn natural language.
The Pile dataset includes more than 1 million books, over 500 million documents, and more than 6 billion words. It is divided into two parts: training and validation data. The training data is used to train the language model, while the validation data is used to evaluate the performance of the model.
The Pile dataset is designed to provide a broad range of text for language modeling tasks. It can be used in applications such as text classification, sentiment analysis, and question answering. Additionally, the dataset can be used to improve existing language models or to create new ones.
Finally, the Pile dataset is available for free and can be downloaded from the AI2 website. It is an important resource for anyone working on natural language processing or related fields.
Get in touch with The Pile

edited by
John Smith is a freelance writer with over a decade of writing experience in the tech industry. John is not just a writer, but also a geek and developer who has a passion for exploring new AI-powered tools and GPT-3 & GPT-4 apps. He is an enthusiast in the field of artificial intelligence and regularly writes about the latest advancements in the industry. When John is not writing, you can find him tinkering with new coding languages or spending time with his family. His mission is to bridge the gap between technology and the everyday user through his writing.


