 New
New
 Free
Free
 Home
Home

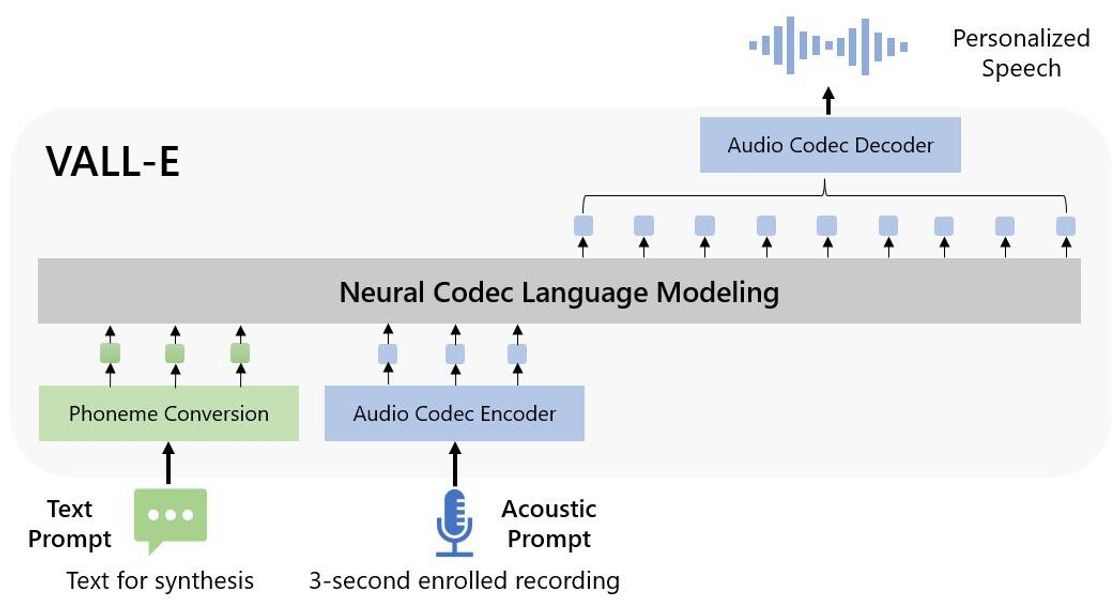
VALL-E is a revolutionary new technology that uses only 3 seconds of audio to simulate anyone's voice. It offers a powerful and cost-effective way to generate realistic, human-like sounds in any language. VALL-E is an artificial intelligence (AI) system that can be used for a variety of applications, such as creating audio-visuals, providing voice-overs for videos, and creating virtual assistants. By leveraging the latest advancements in speech synthesis, VALL-E can accurately replicate the sound of real people with just a few seconds of audio. With VALL-E, businesses, organizations and individuals can now bring their ideas to life with a realistic, natural sounding voice.
Usage: Media
Model: GitHub
Pricing: Contact for Rates
Tags: technology virtual assistants speech synthesis voice simulation human-like sounds
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots
Video Reviews
Similar Tools to VALL-E
-
AudioNotes.ai is a groundbreaking tool designed to revolutionize the way audio content is processed. With its advanced technology, it seamlessly converts any audio file into accurate and easily accessible text notes. This innovative solution caters to students, professionals, and researchers who rely on capturing and organizing crucial information from meetings, lectures, interviews, and more. By providing a reliable and efficient transcription service, AudioNotes.ai eliminates the tedious task of manual note-taking, saving valuable time and enhancing productivity. With its user-friendly interface and unparalleled transcription accuracy, AudioNotes.ai is the ultimate tool for converting audio into convenient and searchable text notes.
 Freemium
#Speech Synthesis
Freemium
#Speech Synthesis
-
HappyScribe is a cutting-edge transcription software that utilizes AI technology to convert audio and video files into text with unparalleled accuracy of up to 99.9%. The software simplifies the process of transcription, making it easier for professionals and businesses to generate accurate transcripts in a matter of minutes. With HappyScribe, users can easily extract valuable insights from their audio or video content without having to spend countless hours transcribing manually. It is no doubt that HappyScribe is revolutionizing the way we transcribe and analyze audio and video content.
Freemium
#Speech Synthesis
-
Microsoft Cognitive Services Speech is a revolutionary technology that has transformed the way applications recognize speech and provide tools for speech synthesis. With the help of this advanced platform, developers can easily build intelligent applications that can automatically detect human speech and convert it into text or other forms of data. By leveraging cutting-edge machine learning algorithms, Microsoft Cognitive Services Speech ensures high accuracy and reliability, making it an invaluable tool for businesses looking to automate their workflows and enhance the user experience. This article explores the key features and benefits of Microsoft Cognitive Services Speech, and how it is changing the landscape of modern technology.
Contact for Rates
#Speech Synthesis
-
Google Cloud Speech API is a remarkable tool for developers, offering them an efficient solution to convert audio recordings into text. With support for over 80 languages, this technology stands out for its ability to transcribe audio from diverse sources, making it an ideal solution for businesses and organizations of all sizes. The Google Cloud Speech API is a powerful tool that can process audio data in real-time, making it an excellent choice for speech recognition applications, transcription services, and more. In this article, we will explore the unique features of the Google Cloud Speech API and how it can benefit developers and businesses alike.
Freemium
#Speech Synthesis
-
Vivox Voice is an innovative AI-powered speech recognition technology that has revolutionized the way developers integrate voice capability into their applications and services. With its advanced algorithms and cutting-edge features, Vivox Voice offers developers a seamless and intuitive platform to enhance the user experience of their products. This technology provides a wide range of benefits, including improved accessibility, increased productivity, and enhanced efficiency. By leveraging Vivox Voice, developers can unlock the full potential of their applications and services, delivering an exceptional user experience that sets them apart from the competition.
Contact for Rates
#Speech Synthesis
-
AppTek Automated Speech Recognition offers an advanced technology that allows users to transcribe audio data into text with speed and accuracy. With cutting-edge algorithms, this solution is capable of processing vast amounts of speech in real-time, making it ideal for businesses and individuals alike. AppTek's recognition technology is designed to remove the burden of manual transcription, thus saving time and resources. Anyone can benefit from this solution, whether you're a journalist or a business owner looking to streamline your workflow. In this article, we will explore the features and benefits of AppTek Automated Speech Recognition in detail.
Contact for Rates
#Speech Synthesis

Top Rated Tools
-
ChatGPT Plus
Introducing ChatGPT
Contact for Rates #Alternative Language Model -
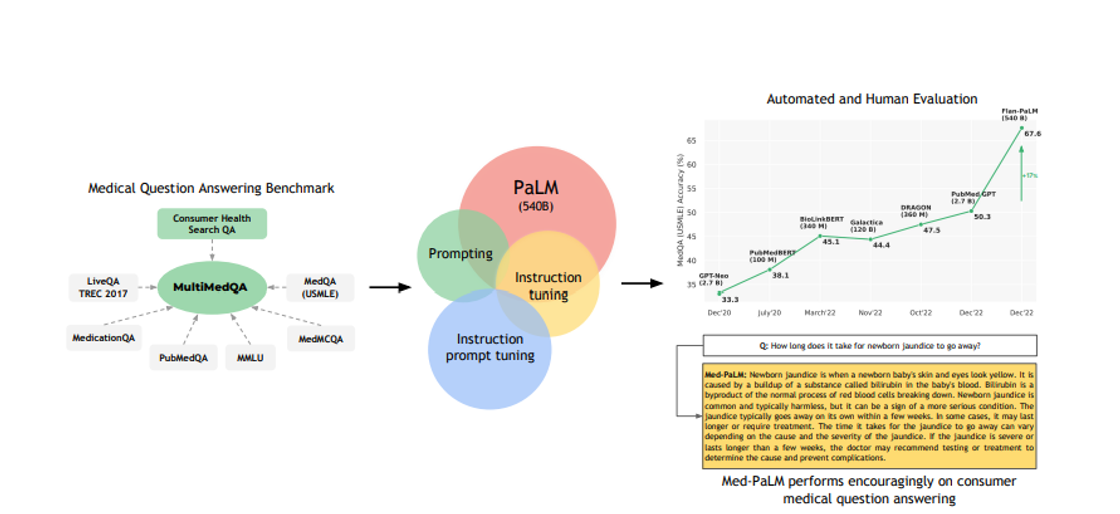
Med-PaLM
AI Powered Medical Imaging
Contact for Rates #Alternative Language Model -
You
The AI Powered Language Model
Free #Generative AI -
Talk To Books
A new way to explore ideas and discover books. Make a statement or ask a question to browse passages from books using experimental AI.
Free #Experiment -
Chai
AI Writing Assistant
Free #Conversation -
Perplexity AI
Building Smarter AI
Free #Chatgpt Alternative -
WatermarkRemover.io
Watermark Remover - Remove Watermarks Online from Images for Free
Freemium #Image Editing -
Picsart
AI Writer - Create premium copy for free | Quicktools by Picsart
Paid #Design Assistant



VALL-E is an amazing new technology that enables people to simulate anyone's voice with only three seconds of audio. This revolutionary technology has the potential to revolutionize how people interact with computers and other digital devices. VALL-E is a form of artificial intelligence that uses machine learning algorithms to analyze a person's vocal sound and create a digital version of their voice. By using this technology, users can create their own personal virtual assistant that can interact with them in a more natural way.
The ability to accurately simulate another person's voice has numerous applications. For example, it could be used to create an automated customer service system, or to create voiceovers for videos and other media. It could also be used to create audio books or to provide virtual assistants for elderly people who can no longer communicate verbally. In addition, it could be used to create synthetic voices for virtual reality experiences.
Overall, VALL-E technology can provide a number of opportunities for people to interact with the digital world in a more natural and personalized way. It can also provide a unique way for people to express themselves, as well as create a more personal connection with their technology. As this technology develops, it has the potential to transform the way people interact with technology.

Top FAQ on VALL-E
1. What is VALL-E?
VALL-E is a voice simulation technology that can replicate anyone's voice using just 3 seconds of audio.
2. How does VALL-E work?
VALL-E uses advanced Artificial Intelligence (AI) to analyze and learn the characteristics of an individual's voice from 3 seconds of audio sample. It then creates a model that can be used to generate new audio with the same characteristics as the original.
3. What can VALL-E be used for?
VALL-E can be used for various applications, such as creating realistic voice simulations for games, films and other media. It can also be used to create automated customer service systems, synthesize speech for digital assistants, and more.
4. How accurate is VALL-E?
VALL-E is highly accurate, allowing users to create very realistic simulations of voices they have heard or recorded.
5. Is VALL-E free to use?
No, VALL-E is not free to use. It is a paid service.
6. Does VALL-E work with all languages?
Yes, VALL-E is designed to work with all languages.
7. How long does it take to generate a voice simulation?
Depending on the complexity of the audio, it can take anywhere from a few minutes to several hours to generate a voice simulation.
8. Can I adjust the pitch/tone of my voice simulation?
Yes, you can adjust the pitch and tone of your voice simulation using the built-in tools.
9. Are there any limitations to VALL-E?
There are some minor limitations, such as the need for a 3 second audio sample and the length of the generated audio clip.
10. Is VALL-E secure?
Yes, VALL-E is a secure technology and all data is encrypted and stored securely.
11. Are there any alternatives to VALL-E?
| Competitor | Difference |
|---|---|
| Lyrebird | Lyrebird requires significantly more audio (one minute) to recreate a voice. |
| Speechelo | Speechelo only supports text-to-speech conversion, not voice simulation from audio. |
| VocaliD | VocaliD requires significantly more audio (five minutes) to recreate a voice. |
| Voiceful | Voiceful does not support voice simulation from audio, instead it specializes in voice recognition. |

Pros and Cons of VALL-E
Pros
- Uses advanced AI technology to quickly and accurately generate audio simulations
- Offers a wide range of voice options to choose from
- Can be used in multiple languages
- Allows users to easily modify the generated audio to fit their own needs
- Delivers a realistic sounding voice simulation with minimal effort required
- Can be used for various applications, such as creating virtual assistants or gaming characters
Cons
- Expensive technology
- Limited to 3 seconds of audio
- Potential for misuse or abuse
- Lack of control over how the voice is used
- Could be seen as unethical or intrusive

Things You Didn't Know About VALL-E
VALL-E is an AI-powered voice simulator created to enable anyone to create a realistic and accurate replication of any voice with just 3 seconds of audio. Its cutting-edge technology means that it can quickly and accurately simulate the voice of anyone. The process is simple: upload a sample audio of the target person’s voice, and VALL-E will synthesize a new audio file that sounds like the target person.
The technology behind VALL-E is based on an AI algorithm called a generative adversarial network (GAN). This algorithm utilizes deep learning to create a realistic and accurate sound-alike voice. It is able to analyze the audio source and create a voice that matches it in pitch, intonation, and other vocal characteristics.
VALL-E could be used for a variety of purposes, from creating realistic voiceovers for videos to giving virtual assistants a more human-like sound. It could also be used in the entertainment industry, providing actors and musicians with a tool to impersonate other people’s voices.
VALL-E is a versatile and powerful tool, but it does come with some limitations. For example, it is not yet able to replicate someone’s voice with perfect accuracy. Additionally, it requires a minimum of 3 seconds of audio to generate an accurate result, so it may not be suitable for shorter recordings.
Overall, VALL-E is a revolutionary voice simulator that can create accurate and realistic sound-alikes of any voice with just 3 seconds of audio. Its versatility makes it a valuable tool for a range of applications, from virtual assistants to video production.

edited by
Mark Roberts is a seasoned writer with over 15 years of experience in the world of freelance writing. Mark has worked with various clients across different industries and is well-versed in crafting engaging content that resonates with his audience. As a tech enthusiast, Mark has a keen interest in AI-powered tools and GPT-3 & GPT-4 apps, and is always on the lookout for new ways to integrate these tools into his work. Mark is a self-confessed geek and loves nothing more than getting lost in a good book or tinkering with new software. When he's not writing, Mark can be found honing his skills as a developer and working on his latest side project.


