 New
New
 Free
Free
 Home
Home


The Voicebox is a groundbreaking text-guided multilingual universal speech generation system, designed to operate at an unprecedented scale. With its ability to generate speech in multiple languages, this cutting-edge technology opens up new possibilities for communication and accessibility. By using text as input, the Voicebox can produce high-quality speech output, making it an invaluable tool for various applications such as virtual assistants, voiceovers, and language learning platforms. Its scalability ensures that it can cater to diverse user needs, making it a promising solution for bridging language barriers and revolutionizing the way we interact with technology.
Usage: Media
Pricing: Contact for Rates
Tags: communication accessibility social networking virtual assistants multiple languages
For more information, jump to:
Videos | Similar Tools | FAQs | Pros and Cons | Facts


Video Reviews
Similar Tools to Voicebox
-
AT&T Natural Voice Text-to-Speech is an innovative technology that has revolutionized the way we communicate. This advanced AI solution can convert speech to text with remarkable accuracy and produce natural-sounding voices that mimic human intonation and inflection. With its cutting-edge features, AT&T Natural Voice Text-to-Speech has become increasingly popular in various industries, including healthcare, education, and entertainment. The exceptional performance of this technology has made it a preferred choice for businesses looking to enhance customer experience and streamline communication processes.
 Paid
#Speech Synthesis
Paid
#Speech Synthesis
-
In today's digital world, text-to-speech technology has gained significant popularity, making it easier for businesses and individuals to communicate and convey their messages effectively. Voice Forge is one such platform that offers a comprehensive solution with its advanced text-to-speech technology, featuring over 20 languages and high-quality natural sounding voices. With its user-friendly interface and cutting-edge technology, Voice Forge has become a go-to platform for those seeking seamless and efficient communication. In this article, we will delve deeper into the features, benefits, and applications of Voice Forge.
Contact for Rates
#Speech Synthesis
-
ReadSpeaker is an innovative cloud-based text-to-speech platform that enables users to convert any written text into audible voice. With its advanced technology, ReadSpeaker can accurately replicate the natural intonation and rhythm of human speech, making it a valuable tool for improving accessibility and engagement in various settings. Whether it's education, e-learning, customer service, or online content consumption, ReadSpeaker is a versatile solution that can cater to diverse needs. This article explores the features, benefits, and applications of this cutting-edge technology and how it can transform the way we interact with written content.
Contact for Rates
#Speech Synthesis
-
The Microsoft Bing Speech API is a cloud-based service that provides cutting-edge speech recognition and text-to-speech conversion capabilities. This innovative technology allows users to convert speech into written text, voice commands, and synthesized speech. With its powerful algorithms and machine learning models, the Bing Speech API can accurately recognize a wide range of languages and dialects, making it an invaluable tool for businesses and developers seeking to create more accessible and user-friendly applications. In this article, we will explore the various features and benefits of the Bing Speech API and how it is revolutionizing the way we interact with digital devices.
Freemium
#Speech Synthesis
-
Nuance Dragon Speech Recognition is an innovative technology that offers natural language understanding speech recognition to its users. With this cutting-edge tool, users can now control various applications and systems simply by using their voice. The software is designed to recognize spoken words and translate them into text or commands, making it a highly efficient tool for professionals in various fields. This introduction highlights the key features of Nuance Dragon Speech Recognition, emphasizing its ability to streamline processes and improve productivity through voice-enabled controls.
Contact for Rates
#Speech Synthesis
-
Welcome to Altered! Our revolutionary technology allows you to transform your voice into something completely different. Imagine being able to change your voice to any of our carefully curated voices or even create your own custom voice. From a soothing natural voice to a deep commanding one, our unique portfolio has it all. With us, you can easily create professional and compelling voice performances that will make you stand out. Let Altered be your go-to platform for augmentation and enhancement of your voice.
Paid
#Audio Editing
Top Rated Tools
-
AI Roguelite
AI Roguelite on Steam
Paid #Game Development -
CharacterAI
Personality Insights and Predictive Analytics
Free #Avatar Generation -
Remove.bg
Remove Background from Image for Free – remove.bg
Paid #Image Editing -
Box
Cloud Content Management Platform
Contact for Rates #Content Generation -
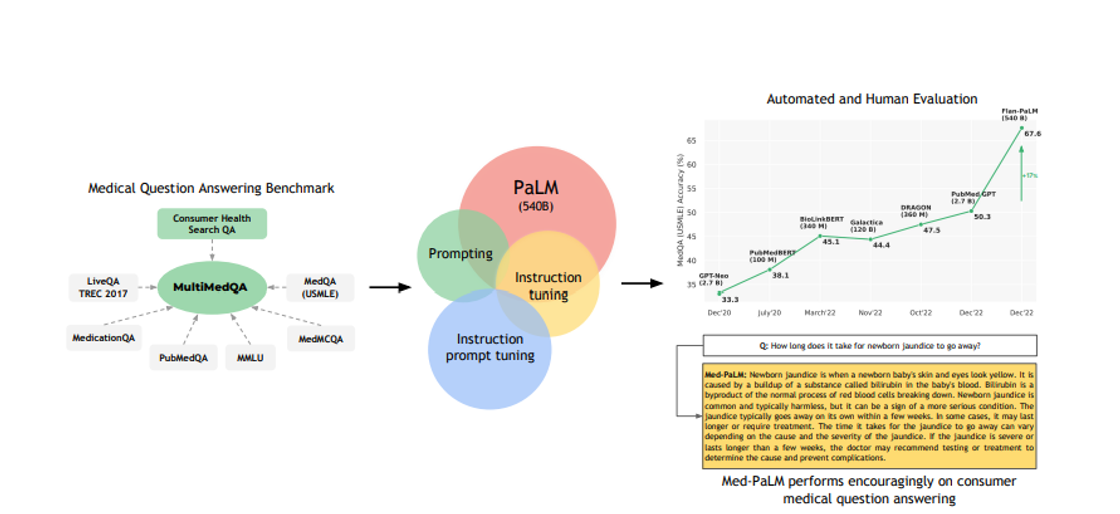
Med-PaLM
AI Powered Medical Imaging
Contact for Rates #Alternative Language Model -
Intercom
Announcing Intercom's New AI Customer Service Features
Contact for Rates #Customer Service -
InVideo
AI-Powered Video Creation
Freemium #Video Editing -
Remini
Remini - AI Photo Enhancer
Paid #Image Editing


The advancement of natural language processing and speech generation technologies has sparked various breakthroughs in human-machine interaction. However, the development of high-quality, multilingual speech synthesis systems remains a challenge. In recent years, researchers have made significant progress in addressing this issue by exploring innovative approaches. One such approach is the Voicebox system, a text-guided multilingual universal speech generation model designed to operate at scale.
Voicebox aims to bridge the gap between different languages and cultures, providing a seamless speech synthesis experience for users across the globe. By harnessing the power of deep learning techniques, Voicebox leverages large-scale multilingual datasets to train its speech generation model. Through this approach, it learns the nuances and intricacies of multiple languages, enabling it to generate high-quality speech in a wide range of linguistic contexts.
What sets Voicebox apart from previous systems is its ability to generate speech that is not only linguistically accurate but also natural-sounding and expressive. The model is trained to mimic human-like intonation, stress patterns, and prosody, allowing it to deliver speech that sounds authentic and engaging. This breakthrough in speech synthesis opens up new possibilities for applications such as voice assistants, audiobook narration, language learning tools, and more.
Furthermore, Voicebox's scalability ensures that it can handle vast amounts of data and accommodate diverse user demands. This makes it a valuable tool for both individual users seeking personalized speech synthesis and organizations requiring large-scale multilingual solutions.
In this paper, we delve into the architecture and training process of the Voicebox system, highlighting its key features and showcasing its performance across various languages. Our findings demonstrate the potential of Voicebox in revolutionizing the field of multilingual speech generation, paving the way for enhanced human-machine communication on a global scale.

Top FAQ on Voicebox
1. What is Voicebox - Text-Guided Multilingual Universal Speech Generation at Scale?
A: Voicebox is an advanced technology that generates multilingual speech by utilizing written text as guidance.
2. How does Voicebox generate speech?
A: Voicebox uses complex algorithms and machine learning models to convert text into natural-sounding speech in multiple languages.
3. Can Voicebox generate speech in any language?
A: Yes, Voicebox has the capability to generate speech in various languages, making it a universal tool for multilingual speech synthesis.
4. Is the generated speech by Voicebox human-like?
A: Yes, Voicebox aims to create natural-sounding speech that closely resembles human speech patterns, intonations, and accents.
5. Does Voicebox have limitations in terms of input text length?
A: While Voicebox can handle both short and long texts, there may be limitations on extremely lengthy texts due to computational constraints.
6. Can Voicebox be used for real-time applications?
A: Yes, Voicebox can be integrated into real-time applications such as voice assistants, virtual agents, or any system that requires speech synthesis on the fly.
7. What are some potential applications of Voicebox?
A: Voicebox can be used in various domains, including interactive voice response systems, audiobook narration, language learning platforms, and more.
8. Is Voicebox available as an API or software package?
A: Yes, Voicebox offers an API and software package that developers can utilize to integrate speech generation capabilities into their applications.
9. Are there any privacy concerns related to using Voicebox?
A: Voicebox respects user privacy and data protection regulations. It does not store or retain personal data from text inputs used for speech generation.
10. Can Voicebox adapt to different accents and speech styles?
A: Yes, Voicebox has been trained on diverse linguistic data, enabling it to mimic various accents, speech styles, and dialects for more personalized speech synthesis.
11. Are there any alternatives to Voicebox?
| Competitor | Difference |
|---|---|
| Google Cloud Text-to-Speech | Voicebox focuses on multilingual support, while Google Cloud Text-to-Speech offers a wider range of customization options. |
| Amazon Polly | Voicebox focuses on multilingual support and universal speech generation at scale, while Amazon Polly offers a more comprehensive set of voices and advanced speech synthesis techniques. |
| Microsoft Azure Speech Services | Voicebox emphasizes multilingual support, while Microsoft Azure Speech Services provides a broader range of speech-related services such as speech recognition, translation, etc. |
| IBM Watson Text to Speech | Voicebox prioritizes multilingual support, while IBM Watson Text to Speech offers a wider array of customization possibilities and integration options. |
| Nuance Communications | Voicebox's main differentiator is its multilingual support and scalability, while Nuance Communications is known for its advanced natural language processing capabilities. |

Pros and Cons of Voicebox
Pros
- Enables multilingual speech generation at scale: Voicebox allows the generation of speech in multiple languages, making it a versatile tool for various applications and users worldwide.
- Provides high-quality and natural-sounding speech: The technology behind Voicebox ensures that the generated speech is of excellent quality and sounds realistic, enhancing the user experience.
- Supports text-guided speech generation: Voicebox can generate speech based on input text, allowing users to have control over the desired content and message conveyed.
- Offers universal application: Voicebox's capabilities make it suitable for a wide range of applications, including voice assistants, audiobook production, language learning platforms, and more.
- Facilitates seamless integration: Voicebox can be easily integrated into existing systems and platforms, enabling developers to incorporate speech generation effortlessly.
- Enhances accessibility: By providing speech output, Voicebox helps make digital content more accessible to individuals with visual impairments or those who prefer auditory information.
- Empowers personalization: Voicebox allows users to customize their generated speech by adjusting factors such as voice style, tone, and speaking rate, adding a personal touch to their applications.
- Complies with privacy standards: Voicebox prioritizes user privacy and data protection, ensuring that any generated speech does not compromise confidentiality.
Cons
- One of the cons of Voicebox is that it may struggle with accurately generating speech in certain languages or dialects. This can lead to distorted or unnatural-sounding output.
- Another limitation is that Voicebox may lack contextual understanding, resulting in incorrect emphasis or intonation in the generated speech. This can affect the overall quality and fluency of the audio.
- A potential drawback of Voicebox is the reliance on text prompts for guiding the speech generation process. This means that the system may struggle with capturing and accurately expressing emotions, sarcasm, or other subtle linguistic nuances.
- Voicebox may face challenges in accurately handling complex or technical content. It could produce errors or misinterpretations when generating speech for such material, leading to inaccuracies or loss of important information.
- Due to the large-scale nature of Voicebox, there may be limitations in terms of customization and personalization options. The system's output may not cater to individual preferences or specific requirements.
- Lastly, as with any AI-based technology, concerns regarding privacy and data security may arise. Users may worry about the storage and usage of their voice data while using Voicebox.

Things You Didn't Know About Voicebox
Voicebox is a revolutionary technology in the field of speech generation, capable of producing multilingual and universal outputs on a large scale. This advanced system has several key features that make it a game-changer in the industry.
First and foremost, Voicebox utilizes text-guided techniques, ensuring accurate and context-aware speech generation. By incorporating natural language processing algorithms, the system can grasp the nuances of written text and deliver speech with exceptional clarity and coherence.
One of the most remarkable aspects of Voicebox is its ability to generate speech in multiple languages. By leveraging extensive language datasets and high-quality voice models, the system can effectively produce speech outputs in various languages, meeting the needs of a global audience.
What sets Voicebox apart from other speech generation systems is its scalability. With the capacity to handle large-scale operations, it can generate speech at an impressive speed without compromising on quality. Whether it's for commercial applications or research purposes, Voicebox proves to be highly efficient and reliable.
Moreover, Voicebox excels in preserving the unique voice characteristics of different speakers. By employing state-of-the-art techniques like speaker adaptation and voice transfer, it can mimic specific voices accurately. This feature opens up numerous possibilities, from creating personalized virtual assistants to generating dialogue for characters in video games and movies.
To ensure the integrity of its outputs, Voicebox undergoes meticulous quality assurance processes. With rigorous testing and validation procedures, the system minimizes errors and inconsistencies, making it a trustworthy tool for professionals in various domains.
In conclusion, Voicebox is a text-guided, multilingual, and universally applicable speech generation technology that offers unparalleled capabilities. Its ability to process and generate speech in multiple languages, along with its scalability and attention to detail, makes it a cutting-edge solution for organizations and individuals seeking high-quality and context-aware speech synthesis.

edited by
Mark Roberts is a seasoned writer with over 15 years of experience in the world of freelance writing. Mark has worked with various clients across different industries and is well-versed in crafting engaging content that resonates with his audience. As a tech enthusiast, Mark has a keen interest in AI-powered tools and GPT-3 & GPT-4 apps, and is always on the lookout for new ways to integrate these tools into his work. Mark is a self-confessed geek and loves nothing more than getting lost in a good book or tinkering with new software. When he's not writing, Mark can be found honing his skills as a developer and working on his latest side project.


