 New
New
 Free
Free
 Home
Home


Voicebox by Meta is an exceptional generative AI model for speech that revolutionizes the field of speech synthesis. Its unparalleled capability lies in its ability to adapt and excel at tasks for which it was not primarily trained, boasting state-of-the-art performance levels. What sets Voicebox apart from existing speech synthesizers is its remarkable versatility. It can be trained using a wide array of unstructured data without necessitating meticulously labeled inputs. This unique feature expands the model's horizons, providing endless possibilities for accurately generating high-quality speech in various applications.
Usage: Media
Pricing: Contact for Rates
Tags: unstructured data versatility speech synthesis Meta high-quality speech
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots

Video Reviews
Similar Tools to Voicebox By Meta
-
In today's fast-paced world, customer support is an essential aspect of most businesses. It can be time-consuming and expensive to manage the high volume of support tickets. Polly.ai is a conversational AI platform that offers a solution to this challenge. With its advanced technology, Polly.ai enables businesses to create virtual assistants that can handle customer inquiries, reducing the number of support tickets. This innovative tool makes customer support more efficient, saving time and money for businesses while delivering a better experience to customers.
 Free Trial
#Speech Synthesis
Free Trial
#Speech Synthesis
-
CMU Pocketsphinx is a speech recognition engine that is lightweight and ideal for use in embedded systems. It has been designed specifically to operate efficiently in resource-constrained environments, such as mobile devices and Internet of Things (IoT) devices. This recognition engine is a product of Carnegie Mellon University's Speech Group, which has been at the forefront of research in speech processing and language technologies for several decades. With its small footprint, high accuracy, and compatibility with various programming languages, CMU Pocketsphinx is an excellent solution for developers who need a reliable and efficient speech recognition system for their embedded applications.
Free
#Speech Synthesis
-
Voicegain Speech Cloud is an innovative cloud-based platform that uses advanced artificial intelligence (AI) technology to convert speech into text with high accuracy. This cutting-edge system has been designed to streamline the process of speech-to-text transcription, helping users to save time and resources while ensuring maximum accuracy. With Voicegain Speech Cloud, businesses and individuals can easily transcribe voice recordings, webinars, meetings, and other audio content with ease, enabling them to focus on more important tasks. This platform has revolutionized the way we convert speech to text, making it faster, more efficient, and more accessible than ever before.
Contact for Rates
#Speech Synthesis
-
Telisma Speech Recognition is a state-of-the-art technology that offers an efficient and reliable cloud-based solution for converting speech to text. With its advanced speech recognition capabilities, Telisma Speech Recognition has become a popular tool for businesses and individuals who require accurate and speedy transcription of audio recordings. This innovative technology has transformed the way people interact with their devices, making it easier to communicate and get things done. In this article, we will explore the features and benefits of Telisma Speech Recognition and show you how it can enhance your productivity and efficiency.
Contact for Rates
#Speech Synthesis
-
Replica Voice is a revolutionary AI-powered platform that allows users to generate authentic-sounding voice performances for their creative projects. The platform uses a sophisticated algorithm that learns the speech patterns, pronunciation, and emotional range of a trained voice actor. With Replica Voice, anyone can create natural-sounding voiceovers for their videos, podcasts, and other multimedia content. It is the perfect solution for individuals and businesses in need of professional-quality voice acting without the high costs and time-consuming process of hiring a human voice actor.
Paid
#Speech Synthesis
-
Gone are the days of having to read through long articles. Thanks to Article.Audio, you now have the option to listen to articles instead of reading them. This innovative program allows you to convert any article into an audio file, so you can listen while you're on the go or just too lazy to read. Article.Audio is the perfect solution for those who want to stay up to date on the latest news and information without having to spend hours reading.
Free
#Speech Synthesis

Top Rated Tools
-
AI Roguelite
AI Roguelite on Steam
Paid #Game Development -
CharacterAI
Personality Insights and Predictive Analytics
Free #Avatar Generation -
Jasper Chat
Jasper Chat | AI Chat for Content Creators
Contact for Rates #Chatbot -
RestorePhotos
Face Photo Restorer
Free #Image Editing -
Speechify
Best Free Text To Speech Voice Reader | Speechify
Paid #Productivity -
Clippy AI
AI-Powered Writing Assistant
Free #Code Assistant -
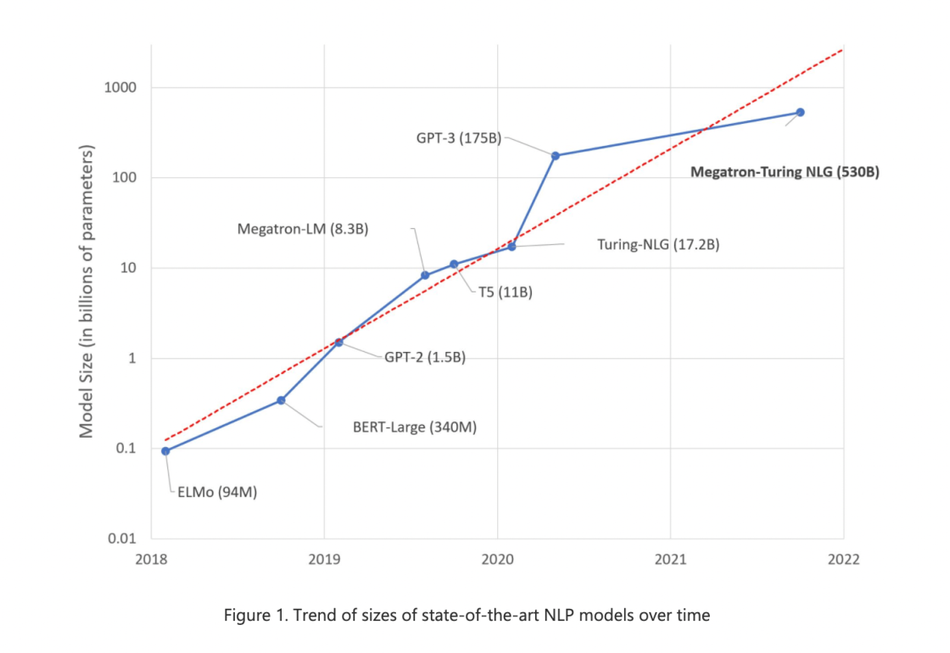
Megatron NLG
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model | NVIDIA Technical Blog
Contact for Rates #Alternative Language Model -
Perplexity AI
Building Smarter AI
Free #Chatgpt Alternative

Meta's Voicebox is a groundbreaking generative AI model designed for speech synthesis, capable of achieving state-of-the-art performance even in tasks it has not been explicitly trained for. Unlike other existing speech synthesizers, Voicebox has the unique ability to be trained using diverse and unstructured datasets, eliminating the need for meticulously labeled inputs.
The remarkable feature of Voicebox lies in its exceptional generalization capabilities. By leveraging cutting-edge techniques, this AI model can adapt to various speech-related tasks beyond its initial training, demonstrating unparalleled performance across a wide range of applications.
Thanks to its capacity to learn from diverse data sources, Voicebox opens up new possibilities for speech synthesis development. It minimizes the reliance on annotated datasets, making the training process more flexible and efficient. This breakthrough not only saves substantial time and resources but also extends the applicability of speech synthesis technology to domains that lack extensive labeled data.
Meta's Voicebox is poised to revolutionize the field of speech synthesis by breaking free from the limitations of traditional models. With its ability to generalize to unseen tasks and learn from unstructured data, this innovative AI model sets a new standard for high-performing and adaptable speech synthesis systems.

Top FAQ on Voicebox By Meta
1. What is Voicebox by Meta?
Voicebox by Meta is a generative AI model for speech that utilizes advanced technology to generate speech with exceptional performance.
2. How does Voicebox differ from existing speech synthesizers?
Unlike existing speech synthesizers, Voicebox can be trained using diverse and unstructured data without the need for meticulously labeled inputs.
3. Can Voicebox perform tasks it was not specifically trained for?
Yes, Voicebox has the ability to generalize to tasks it was not specifically trained for while maintaining state-of-the-art performance.
4. What kind of data can be used to train Voicebox?
Voicebox can be trained on diverse datasets, including unstructured data, which makes it highly flexible in terms of input sources.
5. Is Voicebox limited in its application to certain speech tasks?
No, Voicebox is designed to be versatile and adaptable across various speech tasks, demonstrating its ability to generalize beyond specific training.
6. Does Voicebox require extensive labeling of input data?
No, Voicebox can be trained without requiring carefully labeled inputs, saving time and effort in the training process.
7. How well does Voicebox perform compared to other speech models?
Voicebox achieves state-of-the-art performance, surpassing many existing speech synthesis models in terms of quality and accuracy.
8. Can Voicebox handle different accents and dialects?
Yes, Voicebox has been trained on diverse data, enabling it to handle a wide range of accents and dialects with impressive results.
9. Are there any limitations to Voicebox's performance?
While Voicebox is highly advanced, like any model, it may have some limitations depending on the complexity of the speech task and the nature of the input data.
10. Will Voicebox continue to improve over time?
Yes, Meta is committed to continuous improvement, and Voicebox will undoubtedly benefit from ongoing advancements in AI technology to enhance its performance and capabilities.
11. Are there any alternatives to Voicebox By Meta?
| Competitor | Description | Difference from Voicebox |
|---|---|---|
| Google Cloud Text-to-Speech | A text-to-speech service by Google Cloud that enables developers to convert text into natural human-like speech. It offers multi-language support and customizable voices. | Requires labeled inputs for training and may not generalize as well to diverse, unstructured data. |
| Amazon Polly | Amazon Web Services' text-to-speech service that uses advanced deep learning technologies to synthesize speech from text. It offers a wide range of lifelike voices and supports multiple languages. | May not perform as well on tasks it was not specifically trained for without additional training or fine-tuning. |
| Microsoft Azure Speech Service | A cloud-based speech-to-text and text-to-speech service by Microsoft Azure. It provides robust speech recognition and synthesis capabilities across different platforms. | May not have the same level of performance as Voicebox in terms of generalizing to new tasks without requiring carefully labeled inputs. |

Pros and Cons of Voicebox By Meta
Pros
- Voicebox by Meta is a generative AI model for speech.
- It has the ability to generalize to tasks it was not specifically trained for with state-of-the-art performance.
- Voicebox can be trained on diverse, unstructured data.
- It does not require carefully labeled inputs like existing speech synthesizers.
Cons
- Limited training data: Voicebox may struggle to perform well on tasks outside of its training data since it is trained on diverse, unstructured data without carefully labeled inputs. Lack of specific training data could impact its ability to generalize accurately.
- Potential for inaccuracies: Since Voicebox can generalize to tasks it was not specifically trained for, there is a possibility that it may generate inaccurate or misleading results in certain scenarios.
- Lack of fine-tuning options: The model may not have enough flexibility for fine-tuning to meet specific requirements, as it is designed to work without requiring carefully labeled inputs. This limitation could be a drawback for users looking for more customizable options.
- Dependence on external factors: Voicebox's performance might be influenced by external factors such as ambient noise or vocal characteristics, which could affect the quality and accuracy of generated speech.
- Learning curve for users: Users who are not familiar with generative AI models might face a learning curve while understanding and utilizing Voicebox effectively, potentially limiting its accessibility for non-expert users.

Things You Didn't Know About Voicebox By Meta
Voicebox by Meta is an advanced generative AI model for speech that exhibits exceptional performance even on tasks it was not explicitly trained for. This unique characteristic sets it apart from conventional speech synthesizers. One of its key strengths lies in its ability to be trained using diverse and unstructured data, eliminating the need for meticulously labeled inputs. This groundbreaking technology allows Voicebox to generalize proficiently and deliver state-of-the-art results.

edited by
Jack Richards is a self-proclaimed geek and AI enthusiast who has been freelancing as a writer for over a decade. With a rich writing experience in various niches, Jack's love for technology led him to explore the world of AI-powered tools and GPT-3 & GPT-4 apps. He has been fascinated with the possibilities that AI can bring to the writing world, and spends much of his time experimenting with different tools and software. Jack's passion for writing and technology has led him to create some of the most unique and thought-provoking content in his field, making him a recognized name among the writing community.


