 New
New
 Free
Free
 Home
Home

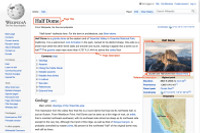
Google AI's WIT is a powerful dataset designed to facilitate multimodal and multilingual machine learning. It is based on Wikipedia, the world's largest online encyclopedia. This dataset is composed of images and text from multiple languages in order to provide a comprehensive resource for researchers and developers. Through this dataset, Google AI is able to promote research and development in the fields of machine learning and computer vision.
Usage: Data
Model: GitHub
Pricing: Contact for Rates
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts


Product Screenshots
Video Reviews
Similar Tools to WIT By Google AI
-
Startups.fyi is a curated database of the best free tools and resources for startup founders to help you build, launch and grow your startup.
 Free
#Database
Free
#Database
-
ProjectEstimates.fyi is a database for home improvement project costs and information. No sign up, address, or personal information is required. Get a sense of what you should expect to pay for a project.
Free
#Database
-
Organize and Manage your Database Easy and simple way to create your database and use the api url perform CRUD operations on your application.
Free
#Database
-
Alteryx is a game-changing analytics platform that enables businesses to explore and predict outcomes with the help of an automated process. This end-to-end platform has revolutionized the way companies approach data analytics, making it easier and more accessible for everyone. With Alteryx, businesses can streamline their analytics process and make informed decisions based on accurate insights. The platform's user-friendly interface and automation capabilities allow users to focus on analyzing data rather than spending time on manual tasks. In this article, we will delve into the key features and benefits of Alteryx and how it can help businesses gain a competitive advantage.
Contact for Rates
#Database
-
SPREEV - One Connect Solutions is revolutionizing the way businesses make decisions by providing an AI-powered platform that enables data-driven decision-making. The platform is equipped with automated machine learning software that can detect and apply the best machine learning algorithms to the data, enabling businesses to make informed decisions quickly and efficiently. Additionally, the platform can seamlessly integrate with multiple sources, making it a versatile solution for businesses of all types and sizes. With SPREEV, businesses can gain a competitive edge by leveraging the power of AI to make informed decisions based on real-time insights.
Contact for Rates
#Database
-
The Pile is an 800GB dataset of diverse text for language modeling. It includes a wide range of texts from literature, news, and web sources, making it one of the most comprehensive datasets for language modeling available. It is a great resource for language researchers and developers working on natural language processing (NLP) tasks such as machine translation, question answering, and other conversational applications.
Contact for Rates
#Database

Top Rated Tools
-
CharacterAI
Personality Insights and Predictive Analytics
Free #Avatar Generation -
Notion AI
Leverage the limitless power of AI in any Notion page. Write faster, think bigger, and augment creativity. Like magic!
Freemium #Notes -
GPT-3 Road Trip Plans For 2021 By CarMax
AI Plans a Road Trip | CarMax
Contact for Rates #Others -
Copy.ai
Copy.ai: Write better marketing copy and content with AI
Paid #Others -
TinyWow
Free AI Writing, PDF, Image, and other Online Tools - TinyWow
Free #Life Assistant -
WatermarkRemover.io
Watermark Remover - Remove Watermarks Online from Images for Free
Freemium #Image Editing -
LALAL.AI
LALAL.AI: 100% AI-Powered Vocal and Instrumental Tracks Remover
Freemium #Audio Editing -
ChatGPT Pro
ChatGPT Plus Access | OpenAI Help Center
Contact for Rates #Chatbot





The world of machine learning is ever-evolving, and the potential for its use in a variety of contexts is increasingly becoming apparent. One of the most exciting areas of research within this field is multimodal and multilingual machine learning, which combines different types of data in order to create new models and applications. An important part of this research is the development of datasets which allow for accurate and comprehensive training and evaluation of these models. WIT by Google AI is a revolutionary new dataset for multimodal and multilingual machine learning, which combines the power of Wikipedia with the vast knowledge of Google AI. This dataset consists of millions of images and text pages, which are linked together using a specialized algorithm. With this dataset, researchers can build powerful models which can accurately predict the contents of images and text, and can be used in a wide range of applications such as image captioning and language translation. The possibilities afforded by WIT by Google AI are limitless, and this dataset has the potential to revolutionize the way machine learning is used in many areas.

Top FAQ on WIT By Google AI
1. What is WIT by Google AI?
WIT by Google AI is a Wikipedia-based image text dataset for multimodal multilingual machine learning.
2. How does WIT by Google AI work?
WIT by Google AI combines images from the web with text from Wikipedia to create a dataset for machine learning models.
3. Where does WIT by Google AI get its data from?
WIT by Google AI gets its data from Wikipedia and web images.
4. What type of machine learning models can be used with WIT by Google AI?
WIT by Google AI is suitable for multimodal, multilingual machine learning models.
5. Does WIT by Google AI provide access to the underlying source code?
No, WIT by Google AI does not provide access to the underlying source code.
6. Is WIT by Google AI open source?
No, WIT by Google AI is not open source.
7. What languages does WIT by Google AI support?
WIT by Google AI supports multiple languages including English, Spanish, French, German, Chinese, Japanese, and Arabic.
8. Is WIT by Google AI free to use?
Yes, WIT by Google AI is free to use.
9. What type of images are included in WIT by Google AI?
WIT by Google AI includes images from various sources including web images, Wikipedia images, and stock photos.
10. How can I get started using WIT by Google AI?
To get started using WIT by Google AI, you can download the dataset from the Google AI website and explore the tutorials and documentation to learn more about the dataset.
11. Are there any alternatives to WIT By Google AI?
| Competitor | Difference from WIT by Google AI |
|---|---|
| ImageNet | ImageNet is a more comprehensive dataset with more than 14 million images and 21,000 object categories. WIT by Google AI only has 300,000 images and 5,000 object categories. |
| Visual Genome | Visual Genome is a large-scale dataset for understanding images that covers over 50k images with more than 3M objects, attributes and relationships. WIT by Google AI only has 300,000 images and 5,000 objects. |
| Open Images | Open Images is a dataset of 9 million images annotated with labels, bounding boxes, segmentation masks, and visual relationships. WIT by Google AI only has 300,000 images and 5,000 objects. |
| Coco | Coco is an image dataset with more than 330,000 images and 80 object classes, with annotations for segmentation masks, keypoints, and captions. WIT by Google AI only has 300,000 images and 5,000 objects. |

Pros and Cons of WIT By Google AI
Pros
- Variety of data and languages: WIT by Google AI provides a wide range of data and multilingual support, making it an ideal dataset for multi-modal machine learning applications.
- High quality images: The images provided in the dataset are of high quality and are suitable for use in a variety of applications.
- Comprehensive coverage: The dataset covers a comprehensive range of topics from Wikipedia, providing users with a valuable source of data for their machine learning tasks.
- Comprehensive annotation: The dataset provides comprehensive annotation for each image, making it easy for users to quickly and accurately identify the content of the image.
- Accessibility: The dataset is freely available, making it accessible to researchers of all levels.
Cons
- Limited coverage and datasets for certain languages
- Low accuracy in recognizing text from images
- Poor performance between languages with different scripts
- Unreliable OCR recognition for certain languages
- Difficulty in linking images to their text descriptions

Things You Didn't Know About WIT By Google AI
WIT by Google AI is an image-text dataset specifically designed for machine learning applications. It contains images with corresponding captions and is based on Wikipedia articles. This dataset is ideal for developers and researchers who are looking to create multimodal, multilingual machine learning models.
WIT by Google AI contains over 300,000 images and corresponding captions in multiple languages, including English, French, German, Spanish, Chinese, Japanese, and Korean. The dataset is split into two sets: training and evaluation. The training set is used for training models, while the evaluation set is used for evaluating the performance of trained models.
The dataset also offers a variety of features, such as image recognition and natural language processing, to facilitate the development of advanced machine learning models. Additionally, WIT by Google AI provides tools for data augmentation and evaluation. These tools help users generate new captions and evaluate the performance of their models.
Finally, the WIT by Google AI dataset offers flexible licensing options that allow developers to customize their models for commercial use. This makes it an ideal choice for developers and researchers who want to create innovative and powerful machine learning models.

edited by
Mark Roberts is a seasoned writer with over 15 years of experience in the world of freelance writing. Mark has worked with various clients across different industries and is well-versed in crafting engaging content that resonates with his audience. As a tech enthusiast, Mark has a keen interest in AI-powered tools and GPT-3 & GPT-4 apps, and is always on the lookout for new ways to integrate these tools into his work. Mark is a self-confessed geek and loves nothing more than getting lost in a good book or tinkering with new software. When he's not writing, Mark can be found honing his skills as a developer and working on his latest side project.


