 New
New
 Free
Free
 Home
Home


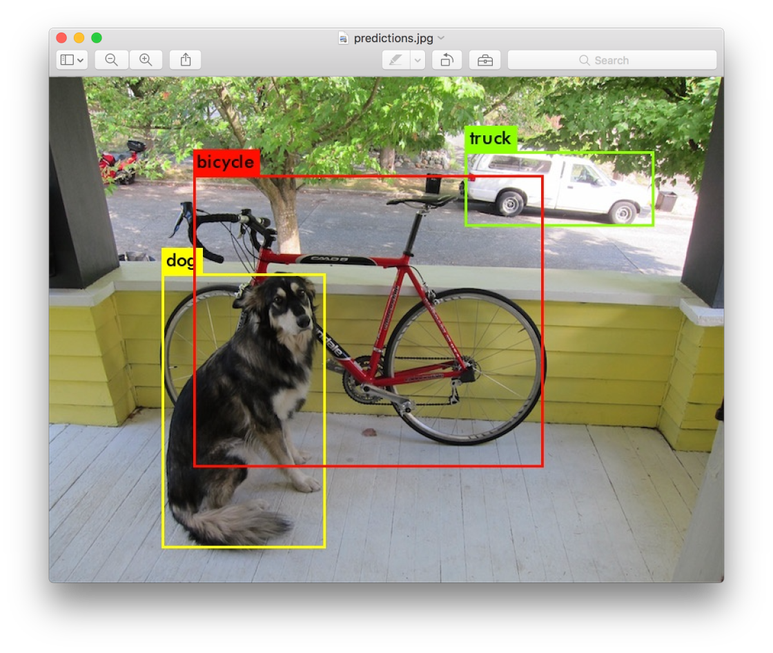
YOLO (You Only Look Once) is a real-time object detection system developed by Joseph Redmon et al. It is an efficient and cost-effective solution for identifying objects in images and videos. YOLO uses deep learning algorithms to detect objects quickly and accurately, and works well even on low-resolution images. This technology has revolutionized the field of computer vision and has made it possible to detect objects without spending too much time or money.
Usage: Other
Pricing: Contact for Rates
Tags: algorithms real-time revolutionized deep learning computer vision
For more information, jump to:
Screenshots | Videos | Similar Tools | FAQs | Pros and Cons | Facts | Contact Info


Product Screenshots
Video Reviews
Similar Tools to YOLO
-
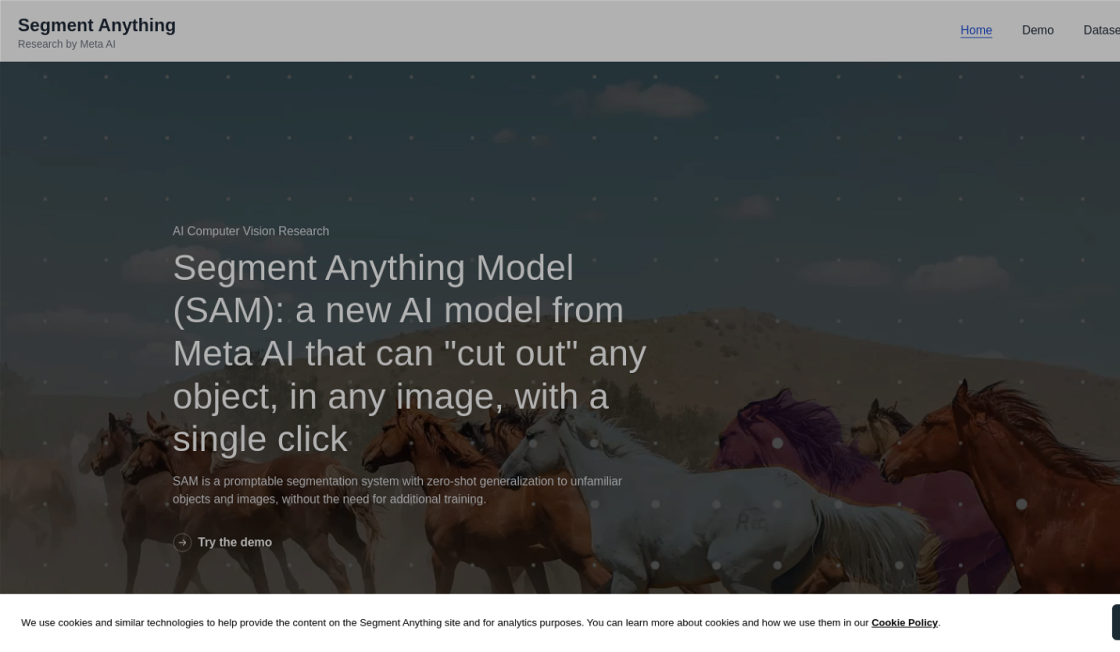
Segment Anything by Meta is a breakthrough AI model that has revolutionized the field of computer vision research. With just a single click, users can now easily segment objects in any image with unparalleled ease and accuracy. What sets this model apart is its unique promptable segmentation system, allowing it to generalize to unfamiliar objects and images without the need for additional training. This capability ensures that users can handle data from a wide range of sources, making Segment Anything by Meta a versatile tool that can be used across various industries. By streamlining the segmentation process, this AI model represents a significant leap forward in the field of computer vision, offering an unprecedented level of speed, accuracy, and flexibility to its users.
 Contact for Rates
#Computer Vision
Contact for Rates
#Computer Vision
-
Cloudsight is a revolutionary cloud-based image recognition and classification platform that enables users to quickly and accurately identify objects, people, and other visual elements in photos and videos. With its advanced machine learning algorithms and powerful computer vision technology, Cloudsight can recognize thousands of objects and concepts with unparalleled accuracy and speed. Whether you're a photographer, marketer, or data analyst, Cloudsight provides an easy-to-use, cost-effective solution for analyzing and categorizing visual content. In this article, we'll explore the key features and benefits of Cloudsight and discuss how it's transforming the way we process and interpret images in today's digital age.
Contact for Rates
#Computer Vision
-
IBM Watson Vision AI is a powerful tool that enables users to analyze images and videos in order to extract detailed information. This technology utilizes computer vision technologies that allow for the identification of objects, people, text, scenes, and activities within visual content. With its advanced capabilities, IBM Watson Vision AI offers a wide range of applications for businesses, researchers, and developers alike. Whether it's analyzing customer behavior, conducting research, or developing new products, this cutting-edge technology has the potential to revolutionize the way we interact with visual data.
Contact for Rates
#Computer Vision
-
IBM Visual Recognition is an innovative technology that utilizes Artificial Intelligence (AI) to analyze and classify objects in images. This technology can detect and recognize various objects within images, including faces, vehicles, animals, and more. Additionally, IBM Visual Recognition has the ability to moderate objectionable content, making it an essential tool for content moderation and ensuring a safe online experience for all users. With its advanced capabilities, IBM Visual Recognition has become a valuable asset for businesses, organizations, and individuals who require accurate and efficient image analysis.
Contact for Rates
#Computer Vision
-
Sightcorp Face Analysis is an advanced AI software that provides facial recognition and analytics services. With the help of cutting-edge technology, this software can accurately detect, track, and analyze facial expressions and emotions in real-time. It is an ideal solution for businesses looking to improve their customer experience through personalized marketing, better engagement, and emotional analysis. The software can also be used for security and surveillance purposes, making it a valuable asset for law enforcement agencies and other organizations. This article will explore the features, benefits, and potential applications of Sightcorp Face Analysis in detail.
Contact for Rates
#Computer Vision
-
Imagga Image Tagging & Multi-Service Platform is a comprehensive platform that offers a variety of services to analyze, tag and categorize images. It is designed to provide accurate and efficient image processing solutions for businesses and individuals. With its advanced features, Imagga Image Tagging & Multi-Service Platform has become a popular choice among photographers, e-commerce sites, and marketers who require an effective tool to manage their image assets. Whether it's image recognition, auto-tagging, or visual search, Imagga Image Tagging & Multi-Service Platform is the ultimate solution for all your image processing needs.
Contact for Rates
#Computer Vision
Top Rated Tools
-
GPT-3 API
An API for accessing new AI models developed by OpenAI.
Contact for Rates #Website Development -
YouChat
AI Chatbot Builder
Contact for Rates #Search Engine -
Ghostwriter
Ghostwriter - Code faster with AI - Replit
Paid #Creative Writing -
LanguageTool
LanguageTool - Online Grammar, Style & Spell Checker
Freemium #Paraphrasing -
GPT-3 Recipe Builder
Generating Cooking Recipes with OpenAI's GPT-3 and Ruby
Contact for Rates #Others -
Twilio
Cloud Communications Platform
Contact for Rates #Customer Service -
GPT For Sheets
GPT for Sheets™ and Docs™ - Google Workspace Marketplace
Free #Generative AI -
Picsart
AI Writer - Create premium copy for free | Quicktools by Picsart
Paid #Design Assistant

The concept of YOLO - Real-Time Object Detection is an exciting one. It has the potential to revolutionize the way people interact with their environment, be it in their homes, on their commute, or at their workplace. YOLO stands for You Only Look Once and is a real-time object detection system that uses deep learning algorithms to detect objects in an image or video frame. The system is able to identify objects quickly, accurately, and reliably. It is a great tool for recognizing objects in videos and images and can be used in a variety of scenarios such as security applications, autonomous vehicles, medical imaging, and robotics. YOLO has been used with great success in a variety of applications, and its popularity continues to grow. This article will explore the basics of how YOLO works, its advantages and disadvantages, and how it can be applied in different contexts.

Top FAQ on YOLO
1. What is YOLO?
YOLO is a real-time object detection system developed by Joseph Redmon and Ali Farhadi. It uses convolutional neural networks to detect objects in images or videos.
2. How accurate is YOLO?
YOLO is extremely accurate, with an average precision of 73.4% on the COCO dataset.
3. What are the benefits of using YOLO?
YOLO provides fast, accurate object detection, which makes it suitable for a variety of applications such as autonomous driving, security systems, robotics, and more.
4. Does YOLO work with all types of objects?
Yes, YOLO can detect all kinds of objects, including people, cars, furniture, animals, and more.
5. What kind of hardware is required to use YOLO?
YOLO can be used on any platform that supports CUDA, including GPUs, CPUs, and mobile devices.
6. Is YOLO open source?
Yes, YOLO is open source and available on GitHub.
7. Does YOLO require a lot of training data?
No, YOLO can work with very little training data.
8. Does YOLO require a lot of computing power?
No, YOLO is designed to be efficient and requires less computing power than other object detection systems.
9. How easy is it to use YOLO?
YOLO is relatively easy to use and has a straightforward API.
10. Does YOLO support multiple languages?
Yes, YOLO supports Python, C++, and Java.
11. Are there any alternatives to YOLO?
| Competitor | Difference from YOLO |
|---|---|
| R-CNN | Slower processing speed and more complex architecture |
| SSD | Shorter training time and less object localization accuracy |
| SPP-net | Shorter detection time and lower recall accuracy |
| Fast R-CNN | More complex architecture and slower processing speed |
| Faster R-CNN | Longer training time and less object localization accuracy |

Pros and Cons of YOLO
Pros
- Fast and accurate real-time object detection
- Lightweight and low computational cost
- Easy to use and deploy
- Supports multiple platforms such as Windows, Mac, Linux, etc.
- Highly customizable for different applications
Cons
- Poor detection accuracy in certain scenarios
- Limited number of labelled datasets available
- Low frame rate resulting in slow processing time
- Unintuitive user interface
- Difficulty in customizing the model to specific tasks

Things You Didn't Know About YOLO
YOLO (You Only Look Once) is a real-time object detection algorithm developed by Joseph Redmon and Ali Farhadi. It was first released in 2015 and has since become a popular choice for many applications such as self-driving cars, security systems, augmented reality, and robotics. YOLO is a single shot detector that can detect multiple objects in a single frame. It works by dividing an image into a grid of smaller regions and then running a convolutional neural network on each region to identify objects.
One of the major benefits of YOLO is its speed. Its single shot detection allows it to process an image in as little as 20 milliseconds. This makes it ideal for applications that require real-time object detection. YOLO also has a high accuracy rate, making it suitable for tasks where accuracy is important.
YOLO is not without its drawbacks however. It has a tendency to misclassify objects and it is not as accurate as some other deep learning models. Additionally, the training process for YOLO is quite complex and requires a large amount of data.
Overall, YOLO is a powerful and efficient tool for real-time object detection. While it has some drawbacks, its speed and accuracy makes it a worthwhile option for many applications.
Get in touch with YOLO

edited by
Jack Richards is a self-proclaimed geek and AI enthusiast who has been freelancing as a writer for over a decade. With a rich writing experience in various niches, Jack's love for technology led him to explore the world of AI-powered tools and GPT-3 & GPT-4 apps. He has been fascinated with the possibilities that AI can bring to the writing world, and spends much of his time experimenting with different tools and software. Jack's passion for writing and technology has led him to create some of the most unique and thought-provoking content in his field, making him a recognized name among the writing community.


